OpenSpec Is All You Need
Come passare dal vibe coding allo Spec Driven Development (SDD) con OpenSpec e orchestrare agenti AI anche su codice esistente


Ho programmato — ogni giorno, nei fine settimana, senza sosta — per più di metà della mia vita. Poi a marzo del 2023 le cose hanno iniziato a cambiare, quando è apparso ChatGPT. Avevo già sentito parlare dell'architettura dei transformers dal paper di Google "Attention Is All You Need" (2017), ma ChatGPT ci ha lasciati tutti a bocca aperta: molti se ne sono innamorati a prima vista, me compreso. Da quel momento è diventato il mio compagno di programmazione. Abbiamo iniziato a programmare in coppia e sono diventato uno dei pionieri di quello che Andrej Karpathy ha battezzato vibe coding.
Che cos'è OpenSpec?
Il codice compila e apri la pull request (PR), ma non è quello che avevi in mente. Non è un bug nell'AI — l'agente ha letto le istruzioni, ha scelto l'interpretazione più plausibile, e ha implementato quella. Si chiama intent drift, e accade perché, a ogni nuovo prompt, l'AI ricalibra la propria comprensione dei tuoi obiettivi.
I vincoli architetturali definiti all'inizio vengono così ignorati silenziosamente, finché il risultato finale non ha più nulla a che fare con quello originale.
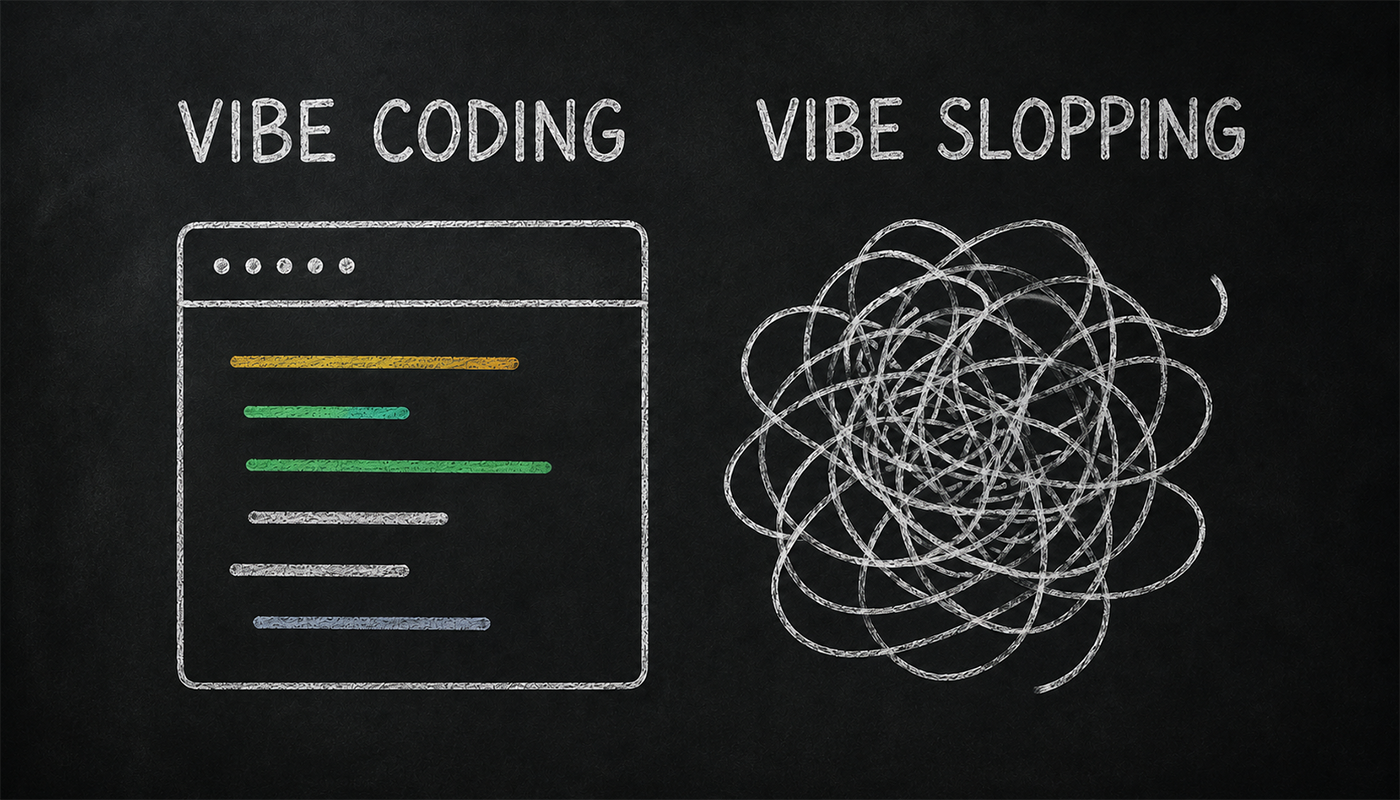
Studi recenti hanno dimostrato che le PR generate dall'AI contengono più problemi rispetto a quelle scritte da esseri umani, che una percentuale significativa dei difetti introdotti da un agente di coding persiste nel repository senza essere mai corretta (🔎Papers [1]) e che l'uso di strumenti AI aumenta le vulnerabilità di sicurezza nel codice prodotto (🔗Sitografia [1]). A questo si aggiunge il fenomeno del vibe slop, codice che sembra funzionare ma che nessuno ha davvero capito o verificato.
OpenSpec nasce per questo. È una metodologia che introduce una fase di specifiche prima di generare codice — così l'AI sa esattamente cosa deve fare, invece di indovinare.
Nessuno parte davvero da zero
La maggior parte dei framework di Spec Driven Development (SDD) assume che tu parta da zero. Peccato che quasi nessun progetto reale parta da zero. Quasi sempre stai lavorando su qualcosa che già esiste — con le sue dipendenze, il suo debito tecnico e le decisioni prese da te o da qualcun altro nel passato.
OpenSpec è costruito con in mente questo scenario.
Le specifiche che scrivi restano nel repository come source of truth — non sai solo cosa il codice fa in questo momento, ma cosa dovrebbe fare. E invece di bloccarti in fasi sequenziali, ti lascia creare gli artifact nell'ordine che ha senso per il tuo lavoro — una proposal per il perché, i delta spec per il cosa, un design per il come, i tasks per le azioni concrete. Ciascuno informa il successivo, ma puoi iniziare da qualsiasi punto.
Quando lavori su codice esistente, l'approccio delta-based fa la differenza — invece di riscrivere specifiche complete, i delta spec descrivono solo ciò che cambia — con sezioni ADDED, MODIFIED e REMOVED.
Le specs restano separate dalle changes, così più persone possono lavorare in parallelo senza conflitti e le revisioni restano pulite.
Iniziare in meno di 30 secondi
OpenSpec si installa in pochi secondi con un singolo comando npm:
# Installare in modo globale con npm
npm install -g @fission-ai/openspec@latest
Per verificare che tutto sia andato a buon fine:
openspec --version
1.3.1Se il comando restituisce un numero di versione, sei pronto. Entra nella cartella del tuo progetto e inizializza:
cd tuo-progetto
openspec init
Il processo interattivo ti chiederà quali strumenti AI usi. In base alla tua scelta, OpenSpec configurerà automaticamente gli skills nella cartella giusta: .claude/skills/ per Claude Code, .cursor/skills/ per Cursor, e così via — compatibile con più di 20 agenti tra cui Codex, GitHub Copilot, Windsurf, Gemini CLI, Cline e molti altri (consulta la documentazione dei tools supportati).
Dopo l'inizializzazione, troverai questa struttura nel tuo progetto:
openspec/
├── specs/ ← source of truth
├── changes/ ← Modifiche proposte (una folder per change)
└── config.yaml ← Configurazione del progetto
OpenSpec eXperience
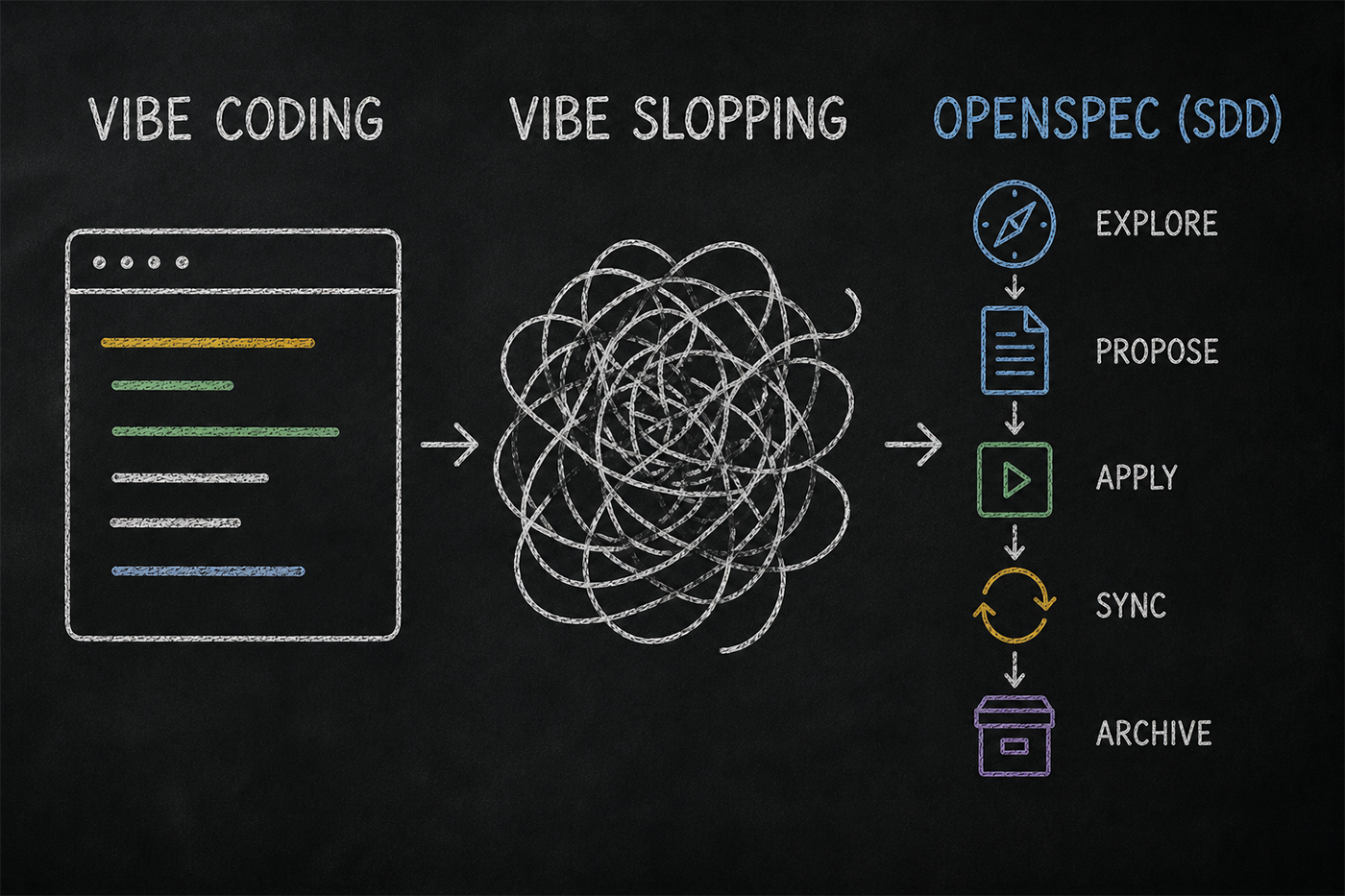
OPSX è il workflow system centrale di OpenSpec. Nasce da un problema preciso — nel legacy workflow le fasi erano bloccate in sequenza — prima la proposal, poi l'implementazione, poi l'archivio. Non potevi tornare indietro senza rompere il flusso. Nella pratica, questo significa che ogni volta che cambiavi idea a metà implementazione — e capita sempre — il sistema si inceppava.
OPSX rimuove queste "phase gates" e introduce un modello fluido — puoi eseguire le azioni in qualsiasi ordine, in base allo stato reale del progetto.
Internamente, OPSX usa un grafo di artefatti — tecnicamente un DAG, directed acyclic graph — che traccia lo stato di ogni artifact all'interno di una change directory. Ogni artifact può essere done (completato), ready (le dipendenze sono soddisfatte, si può procedere) o blocked (mancano dipendenze).
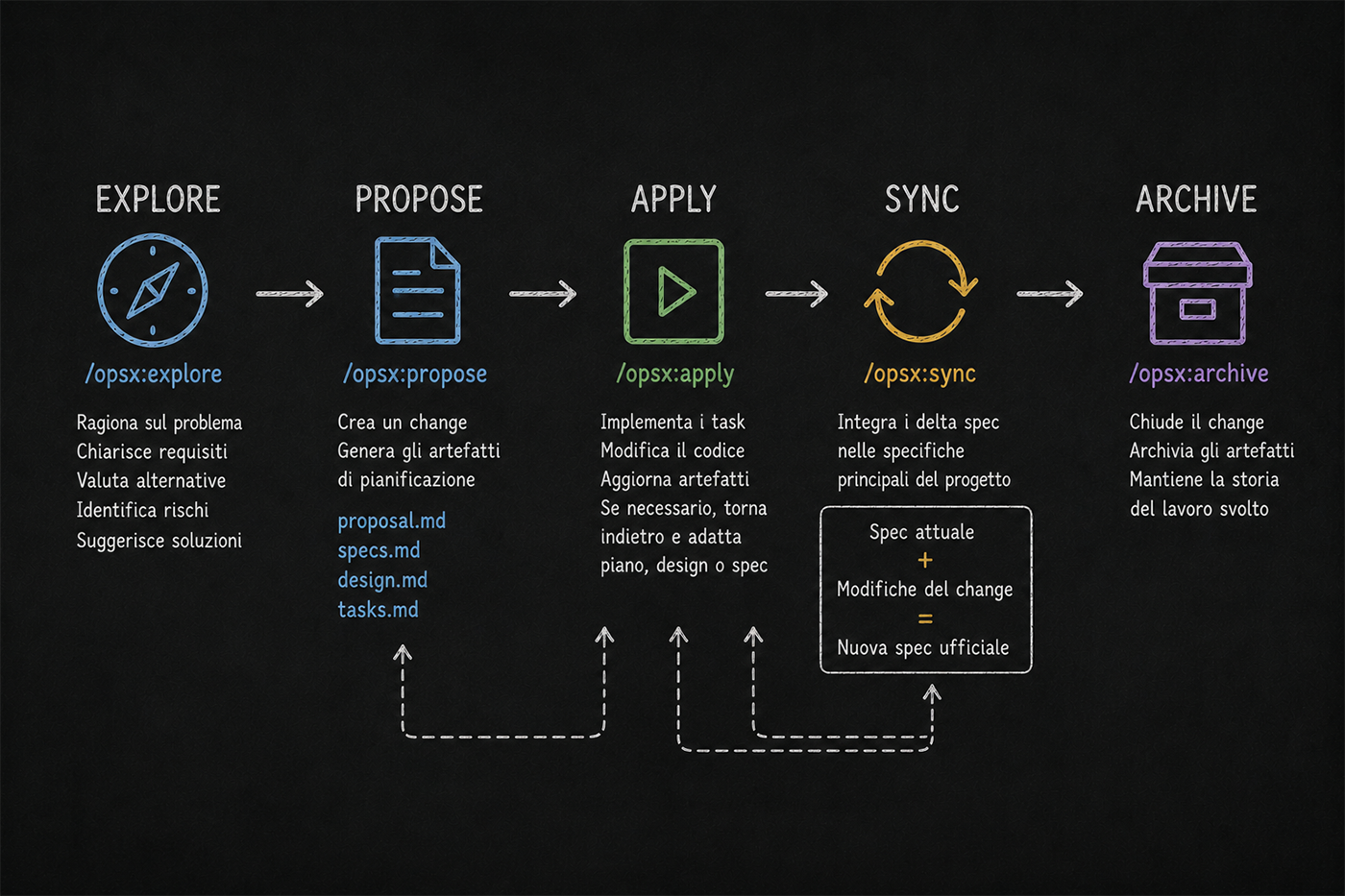
Prima di agire, l'IA interroga la CLI per capire lo stato reale del progetto — non si affida a prompt statici, non lavora su assunzioni. Questo è il motivo per cui OPSX non perde il filo quando cambi idea a metà — il piano vive negli artifact, non nella memoria del modello.
Le istruzioni vengono assemblate dinamicamente in tre livelli — il context (informazioni globali sul progetto, dalla configurazione), le rules (vincoli specifici per ogni tipo di artifact) e il template (la struttura markdown che l'IA va a popolare).
Nel vecchio sistema erano hardcoded in TypeScript e richiedevano una release per essere cambiate. Con OPSX sono file YAML e Markdown editabili direttamente — puoi modificare un template e vedere l'effetto immediato, senza aspettare aggiornamenti del pacchetto.
Dall'idea alla change 🎯
All'interno di OPSX, OpenSpec espone due profili — e la scelta tra uno e l'altro dipende da quanta visibilità vuoi avere su quello che sta facendo l'agente.
Il profilo core — quello attivo per impostazione predefinita — include i 5 comandi che coprono l'intero ciclo di vita di una change: propose, explore, apply, sync, archive. L'agente va da sé: parte dalla proposal, genera tutti gli artifact in un colpo, e procede con l'implementazione. Funziona bene per feature chiare, bug fix, lavoro diretto.
Il profilo espanso aggiunge 6 comandi — new, continue, ff (fast-forward), verify, bulk-archive, onboard — e si attiva con openspec config profile. La differenza non è solo quantitativa: con continue l'agente crea un artifact alla volta e aspetta il tuo ok prima di proseguire. Utile quando il change è complesso, i requisiti sono ancora poco chiari, o vuoi revisionare design e specs prima che l'implementazione parta.
Qualunque profilo tu scelga, c'è un comando che uso sempre per primo. La documentazione ufficiale non lo menziona nemmeno nella getting started — eppure per me è il più importante. Non scrive una riga di codice. Non genera nessun artifact. Ti permette di pensare ad alta voce con l'agente, di scaricare idee grezze, di esplorare senza impegnarti. Uno stream of consciousness — prima che qualcosa diventi una change.
Explore mode (Optional ma Potente!)
Il comando /opsx:explore si comporta come un solution architect —l'agente esplora, fa domande, capisce cosa vuoi davvero costruire, prima di toccare una riga di codice.
Gli fornisco il contesto nel modo che mi è più comodo — un ticket Jira, una issue GitHub, uno screenshot, specs passate. Spesso uso direttamente la dettatura vocale — scarico i miei pensieri senza filtri, senza strutturare niente. Da lì, l'agente esplora il codebase, fa domande mirate per colmare le lacune, mostra diagrammi ASCII per illustrare idee architetturali, mappa i flussi — e se ci sono più modi di risolvere il problema, li presenta insieme a pro e contro.

Potresti pensare che sia la plan mode che tutti gli agenti di coding offrono già. Non lo è — o almeno, va ben oltre. La differenza vera è questa — da quella conversazione l'agente genererà direttamente gli artifact e le specs. Non stai solo pianificando.
Stai producendo gli artifact che guideranno l'implementazione.
Anatomia di una change
Un change in OpenSpec rappresenta l'intero ciclo di vita necessario per progettare e implementare una feature. Dal punto di vista pratico, un change è semplicemente una cartella sul filesystem.
openspec/
├── specs/ ← source of truth
│ ├── auth/
│ │ └── spec.md
│ └── payments/
│ └── spec.md
└── changes/ ← modifiche proposte (una folder per change)
│ ├── add-dark-mode/
│ └── archive/ ← completed changes archived here
└── config.yaml ← Configurazione del progettoProject Structure
Questa cartella raccoglie tutti gli artifact prodotti durante il processo e diventa il luogo in cui viene documentata l'evoluzione della feature, dall'idea iniziale fino al codice finale. Gli artifact vengono generati progressivamente dall'agente seguendo un flusso preciso.
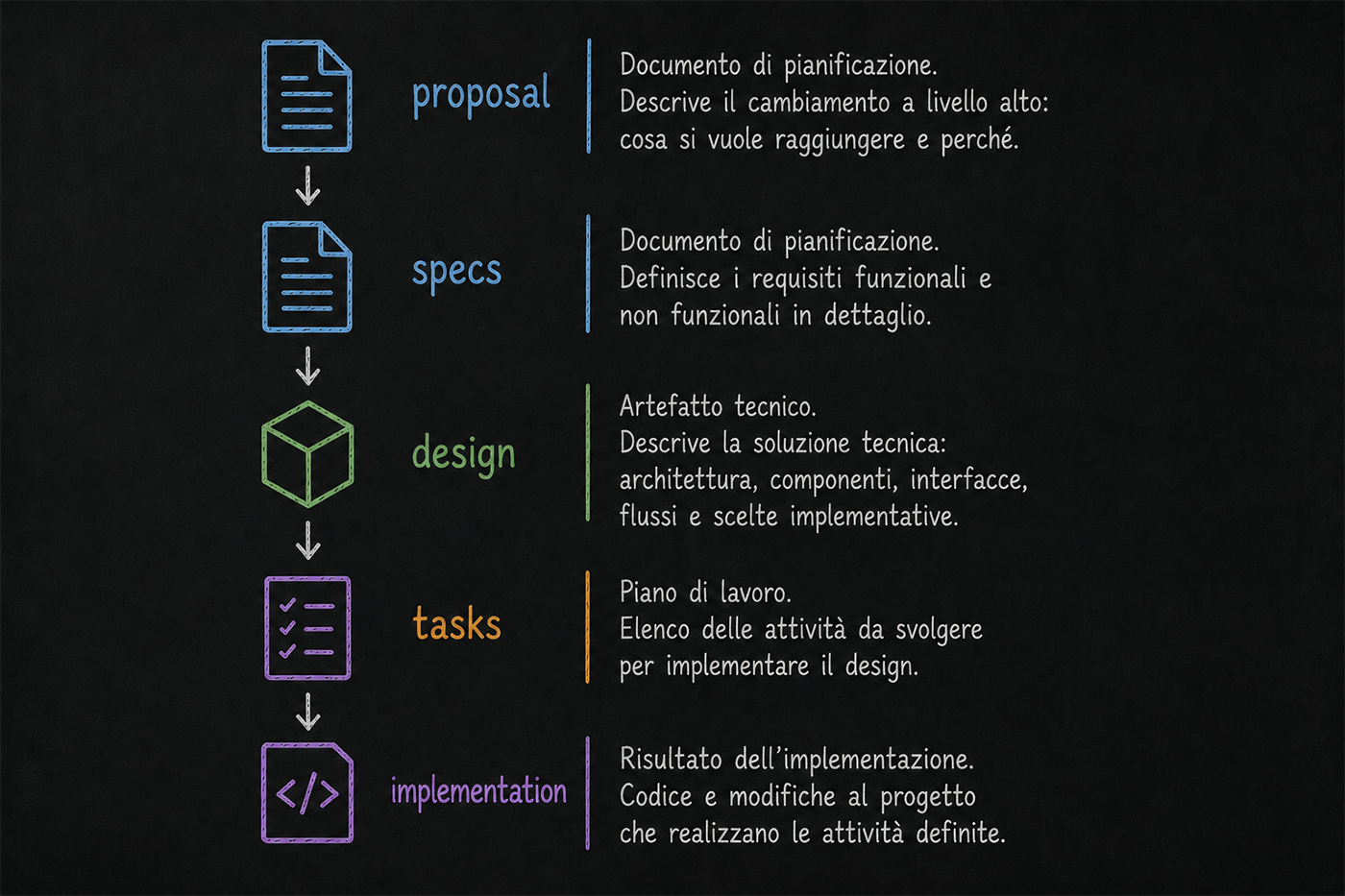
Il primo step è il proposal. Una volta conclusa la fase di exploration e raggiunto un accordo sul piano da seguire, l'agente chiede conferma prima di procedere. In quel momento crea la cartella del change, se non esiste già, e vi salva il file proposal.md, un documento che descrive gli obiettivi della modifica, le ragioni che la motivano e il valore che dovrebbe apportare al progetto.
Dopo il proposal arrivano le specs, che definiscono in modo dettagliato i requisiti funzionali e non funzionali della soluzione. Ogni specifica è scritta in formato Gherkin — uno standard leggibile sia dagli sviluppatori che dai non tecnici — strutturato in tre clausole: GIVEN (il contesto di partenza), WHEN (l'azione che scatena il comportamento) e THEN (il risultato atteso). Questo formato rende i requisiti verificabili e direttamente collegabili ai test automatizzati.
Come si vede nell'esempio qui sotto, ogni requisito funzionale viene tradotto in uno o più scenari concreti, ciascuno con un nome esplicito e una sequenza GIVEN/WHEN/THEN che non lascia spazio ad ambiguità interpretative.
# Auth Specification
## Purpose
Authentication and session management.
## Requirements
### Requirement: User Authentication
The system SHALL issue a JWT token upon successful login.
#### Scenario: Valid credentials
- GIVEN a user with valid credentials
- WHEN the user submits login form
- THEN a JWT token is returned
- AND the user is redirected to dashboard
#### Scenario: Invalid credentials
- GIVEN invalid credentials
- WHEN the user submits login form
- THEN an error message is displayed
- AND no token is issued
Spec Format
Su queste fondamenta viene costruito il design, il documento che descrive l'approccio tecnico scelto, le componenti coinvolte, le interfacce, le dipendenze e le principali decisioni architetturali.
Il passaggio successivo riguarda i tasks, che trasformano la progettazione in un piano di lavoro concreto. Si tratta di una checklist di attività che l'agente aggiorna man mano che procede con l'implementazione. Possiamo aggiungere nuovi task manualmente oppure chiedere all'agente di farlo per noi.
Questo permette di includere anche attività che non riguardano direttamente il codice, come la configurazione di segreti su Key Vault o l'aggiornamento di risorse infrastrutturali. In questo modo diventano parte integrante della definition of done e rimangono tracciate insieme al resto del lavoro.
L'ultimo artifact è implementation, che rappresenta il risultato finale del change. Qui troviamo il codice sorgente e tutte le modifiche necessarie per realizzare quanto descritto nei documenti precedenti.
Uno degli aspetti più interessanti di OpenSpec è che nessuno di questi artifact deve essere necessariamente scritto a mano. L'agente è in grado di generarli automaticamente e mantenerli coerenti tra loro durante l'intero processo. Possiamo intervenire in qualsiasi momento per modificarli, arricchirli o correggerli, ma nella maggior parte dei casi sono già sufficientemente completi da poter essere utilizzati così come vengono prodotti.
Archiving del change
Una volta che l'implementazione è completa, l'agente ti chiederà se vuoi archiviare il change. Questo sposta la cartella del change in una directory archive che diventa uno snapshot della change (proposal, design, tasks, delta al momento dell’archiviazione): serve come storico, non come ramo di lavoro ufficiale.
openspec/
├── specs/ ← source of truth
│ ├── auth/
│ │ └── spec.md
│ └── payments/
│ └── spec.md
└── changes/ ← modifiche proposte (una folder per change)
│ ├── add-dark-mode/ ← in corso
│ └── archive/ ← completed changes archived here
│ └── add-jwt-auth/ ← archiviata
└── config.yaml ← Configurazione del progettoChange Archive Structure
C'è anche un'altro step prima dell'archiving chiamata syncing. La includo in questa sezione perché spesso il passaggio archive lo fa automaticamente per te. Syncing significa che prenderà le delta specs dal change e le applicherà ai file di spec di output.
Una delta spec è semplicemente un file markdown che descrive cosa è cambiato rispetto alla spec esistente. Usa sezioni come ## ADDED Requirements, ## MODIFIED Requirements e ## REMOVED Requirements, ognuna contenente i requisiti rilevanti e i loro scenari.
## ADDED Requirements
## MODIFIED Requirements
## REMOVED Requirements
Quando archivi, OpenSpec prende quelle delta specs dal change e le integra nella spec canonica per quella feature — così la prossima volta che tu (o l'agente) leggi quella spec, hai il quadro completo di tutti i change che hanno toccato quella feature.
Da notare che syncing /archiving crea ulteriori pending Git change — quindi vale la pena farlo prima che la tua PR venga mergiata — altrimenti dovrai creare un'altra PR per quelle modifiche.
Paradigm shift
Though the world does not change with a change of paradigm, the scientist afterward works in a different world. — Thomas Kuhn
Sono passati tre anni.
Il mondo dello sviluppo software non è cambiato, ma ci lavoriamo in modo completamente diverso. Ho iniziato come developer che programmava ogni giorno, poi come vibe coder che scaricava idee in chat, e oggi mi trovo in un ruolo che nessuno aveva previsto — orchestratore di agenti. Non scrivo più codice, scrivo specifiche, e gli agenti implementano.
Questo è il cambio di paradigma alla Thomas Kuhn che stiamo vivendo. Nel vecchio paradigma la competenza chiave era saper scrivere codice; nel nuovo è saper definire l'intenzione con abbastanza precisione da non lasciare spazio all'interpretazione. Perché quando lasci spazio, l'agente lo riempie — e non sempre nel modo che avevi in mente.
OpenSpec nasce da questa consapevolezza. Non è uno strumento per rallentare lo sviluppo — è ciò che ti permette di andare veloce senza perdere il controllo. Le specifiche diventano la tua memoria estesa, il contratto tra te e l'agente, la difesa contro la deriva. L'IA non genera solo più codice — genera anche più responsabilità. E la responsabilità, per ora, è ancora nostra.
Se vuoi provarci e aprire la tua prima change:
npm install -g @fission-ai/openspec@latest 🔗Sitografia
2025
[0] Purvi Sankhe et Al, Empirical Analysis of AI-Assisted Code Generation Tools Impact on Code Quality, Security and Developer Productivity, Research Gate, Novembre 2025
[1] Craig Hale, AI-generated code contains more bugs and errors than human output, Yahoo Tech, 18/12/2025
2026
[0] Reya Vir, The Reality of Vibe Coding: AI Agents and the Security Debt Crisis, Towards Data Science, 22/02/2026
[1] Rajan Raj, Spec-Driven Development with OpenSpec and Claude Code, Medium, 27/02/2026
[2] Hari Krishnan , OpenSpec 1.2 Release, Intent Driven, 25/02/2026
[3] Hari Krishnan, Spec-Driven Development with Brownfield Projects, Intent Driven, 10/03/2026
[4] Redazione, Guía de Spec Driven Development con agentes IA (con OpenSpec), WebReactiva, 17/03/2026
[5] Rick Hightower, Agentic Coding: GSD vs Spec Kit vs OpenSpec vs Taskmaster AI: Where SDD Tools Diverge, Medium, 27/02/2026
🔎Papers
[0] Ashish Vaswani et al., Attention Is All You Need, Arxiv 1706.03762, 12/06/2017
[1] Yue Liu et al., Debt Behind the AI Boom: A Large-Scale Empirical Study of AI-Generated Code in the Wild, Arxiv 2603.28592, 20/03/2026
📺Videografia
2026
[0] Amin Espinoza, Aprende a usar Open Spec en tus proyectos, Youtube, 2026
[1] EDteam, La forma CORRECTA de programar con IA en 2026: Spec Driven Development, Youtube, 2026