Domain-Driven AI: come coinvolgere l'esperto di dominio?🌭
I criteri di valutazione non si definiscono a priori: emergono. Come e quando coinvolgere il domain expert per non sbagliare domanda.


Nel primo articolo abbiamo visto cos'è un domain expert, perché non puoi farne a meno, e come scegliere la persona giusta. Ora la domanda è: una volta che l'hai trovata, come la coinvolgi — e quando?
Not hotdog 🌭
La prima cosa che fai come AI Solution Architect quando devi valutare un sistema AI è cercare una metrica. Qualcosa di oggettivo, scalabile in produzione, che non richieda di chiamare un esperto di dominio ogni volta che vuoi sapere se il sistema funziona. È un impulso naturale — ed è anche il modo più veloce per finire come Jian-Yang.

Jian Yang è un developer della serie Silicon Valley — impassibile, laconico, mai turbato da nulla. La sua idea è ambiziosa: costruire lo Shazam del cibo, un'app capace di identificare qualsiasi pietanza da una fotografia. La chiama SeeFood — un gioco di parole sull'ambizione del progetto. Un investitore abbocca, il pitch regge, il team si mette al lavoro.
Ottimizza il modello fino al 90% di accuracy. La demo è impeccabile: punta la fotocamera su un hotdog, l'app risponde in mezzo secondo. Jared esulta — "Huzzah!" Erlich è in estasi. Dinesh è già convinto di essere ricco. Poi qualcuno punta la fotocamera su una pizza. Not hotdog 🌭. Su un'insalata. Not hotdog🌭. Su qualsiasi cosa non sia un hotdog. Not hotdog 🌭.
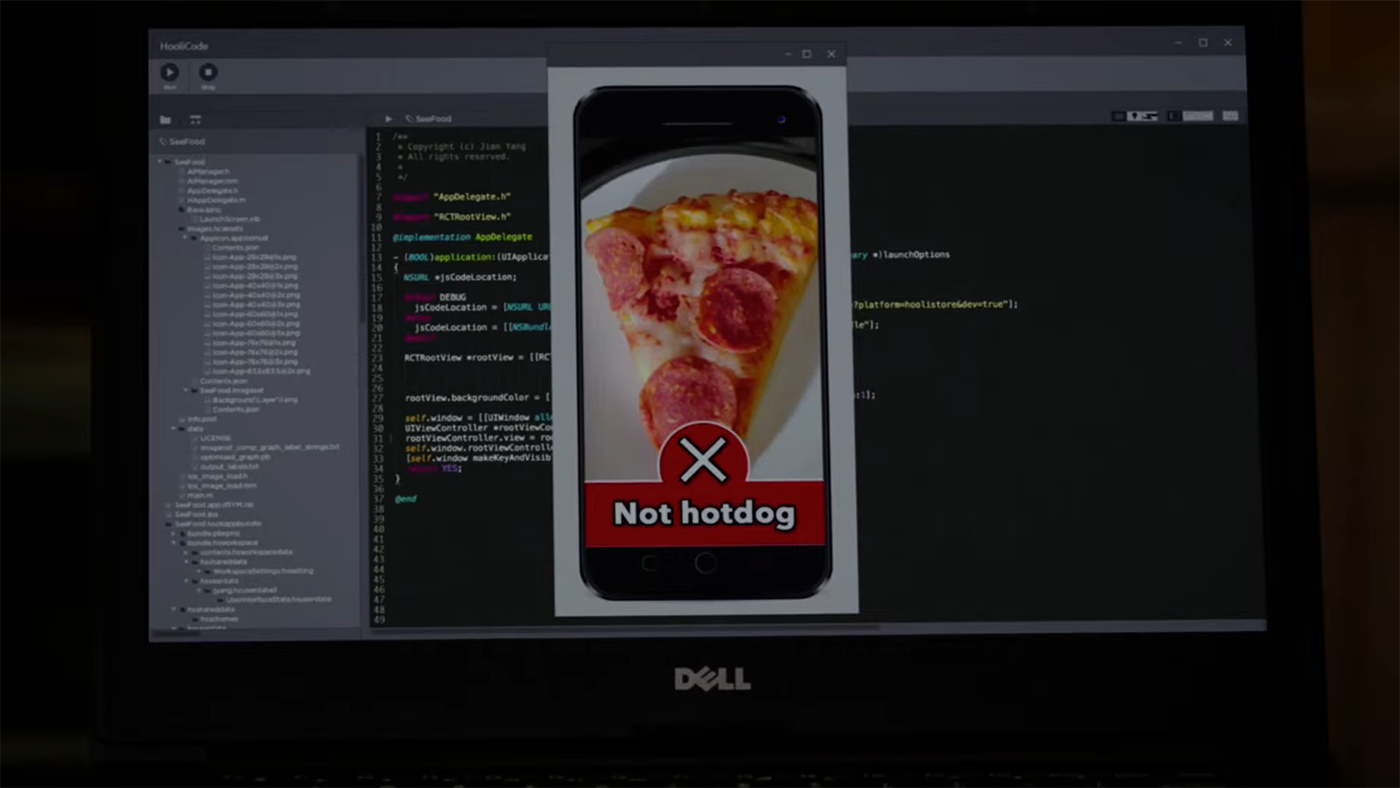
Il problema? SeeFood non identifica il cibo. Identifica gli hotdog — e classifica tutto il resto come "non hotdog". Il 90% di accuracy era reale. Il prodotto non esisteva.
È la stessa trappola di ogni sistema di evaluation mal progettato: ottimizzi per qualcosa di misurabile, e non ti chiedi mai se stai misurando la cosa giusta. Non puoi accorgertene da solo ci vuole qualcuno che conosca il dominio abbastanza da dirti quando il sistema sbaglia, anche quando tutti i tuoi log dicono che ha ragione.
La conoscenza che non è mai stata testo
Prima di affrontare quando coinvolgere l'esperto, vale la pena capire perché il suo contributo è strutturalmente necessario, e non semplicemente utile.
Un domain expert porta con sé qualcosa che non si può estrarre con un questionario: conoscenza tacita. Il filosofo Michael Polanyi la definiva così: "We can know more than we can tell." Il tecnico esperto sa da quale suono capire che un cuscinetto sta per cedere. Il medico sa quando qualcosa "non torna" in un referto. Il linguista sa quando una risposta è grammaticalmente corretta ma pragmaticamente sbagliata.

Questa distinzione ha conseguenze dirette quando si costruisce un sistema AI su un dominio verticale. Gli LLM possiedono alcune forme di conoscenza tacita: riconoscono pattern impliciti nel linguaggio, colgono sfumature mai esplicitamente definite. Ma mancano della forma che Polanyi chiamava incarnata (embodied) — la conoscenza sensoriale e corporea che si acquisisce solo attraverso l'esperienza diretta. Ciò che il tecnico sa non può essere trasferito al modello per via testuale, perché non è mai stato testo.
C'è poi un secondo livello del problema, che riguarda le parole stesse. Wittgenstein osservò che il significato dei termini non è fisso: dipende dal contesto d'uso, da quello che chiamò il gioco linguistico.
Nel dominio della manutenzione industriale, anomalia e guasto non sono sinonimi — sono due stati con conseguenze operative opposte. Un'anomalia è un segnale: c'è ancora tempo, si pianifica un intervento preventivo. Un guasto è un evento: il componente ha già ceduto, il fermo è immediato. Confondere i due in un sistema AI non produce una risposta leggermente imprecisa — produce il piano di intervento sbagliato.
Ho esplorato entrambe queste dimensioni — il limite strutturale degli LLM sulla conoscenza incarnata e la precisione del vocabolario di dominio — nell'articolo "Sappiamo più di quanto sappiamo dire".
Questa conoscenza è implicita, contestuale, costruita nel tempo. Non risiede in documenti, non si trasferisce con un'intervista strutturata, e non si cattura chiedendo all'esperto di "scrivere le regole". Si cattura mettendo l'esperto davanti agli output reali del sistema e osservando dove la sua intuizione si inceppa.
È qui che entra il criterio di valutazione — e qui che la maggior parte dei team sbaglia tempistica.
Criteria drift: prima guardi, poi sai cosa cercare
Il modo più scalabile per valutare un sistema AI in produzione è costruire un LLM-as-a-judge: un secondo modello linguistico che valuta automaticamente gli output del sistema, usando una rubrica — un insieme di criteri espliciti che definiscono cosa è buono e cosa non lo è.
Hai mai provato a scrivere i criteri di valutazione prima di vedere un solo output del sistema? È un esercizio illuminante — e non nel senso positivo. Il problema è che la rubrica deve essere scritta da qualcuno. E quel qualcuno, quasi sempre, prova a scriverla prima di aver visto un solo output reale.
Torna allo Shazam del cibo. Prova a scrivere una rubrica adesso: "L'app deve identificare correttamente il piatto fotografato." Sembra ragionevole. Ma dopo aver guardato i primi cento output reali, ti accorgi che mancano dimensioni che non avevi previsto: l'app identifica il piatto ma ignora gli allergeni. Identifica una portata ma non la variante regionale. Risponde in inglese a un utente italiano.
Il ricercatore Shreya Shankar, nel paper "Who Validates the Validators?" (UIST '24), descrive questo fenomeno come criteria drift: i criteri non possono essere determinati completamente prima che il giudice abbia guardato gli output reali. Il processo di giudicare crea i criteri stessi. Più radicale ancora: alcuni criteri non esistono come entità indipendenti che aspettano di essere scoperti — emergono dall'incontro tra l'esperto e gli output specifici del sistema che sta valutando.
Questo rompe l'assunzione implicita di quasi ogni pipeline di evaluation: che i criteri possano essere definiti a priori, una volta per tutte, e poi applicati meccanicamente. Non funziona così.
È per questo che costruire un LLM-as-a-judge senza prima raccogliere giudizi umani reali è un errore metodologico, non solo pratico. Il tuo domain expert non deve approvare la rubrica a posteriori — deve essere la fonte da cui la rubrica emerge.
Domain Expert: quando coinvolgerlo? 🤔
Il coinvolgimento non è né continuo né uniforme. Capire quando il suo contributo è essenziale fa la differenza tra un processo efficiente e uno che esaurisce l'esperto prima che il lavoro sia finito.
Uno studio etnografico recente (Szymanski et al., IUI '26) ha osservato per dodici settimane un team che costruiva un chatbot pedagogico con un domain expert integrato nel processo. Il risultato più netto: i team che coinvolgono l'esperto tardivamente — solo nella fase di validazione — devono poi tornare indietro a ridefinire criteri e dataset. Il costo del ritardo è alto, e spesso invisibile finché non è già accumulato.
Fase 1 – Definire le domande giuste
Il domain expert non viene coinvolto per costruire dati, ma per definire le dimensioni rilevanti della valutazione. Domande chiave: cosa distingue un'interazione riuscita da una fallita? Quali casi critici il sistema deve assolutamente gestire bene? Quali scenari sarebbero imbarazzanti o dannosi se il sistema li sbagliasse?
Questa fase non richiede molto tempo — ma orienta tutto il resto. Saltarla significa costruire un sistema di valutazione preciso ma orientato verso le domande sbagliate.
Fase 2 – Il dataset come specchio del dominio
Il dataset iniziale può essere costruito usando dati reali o generando esempi sintetici con un LLM. Il domain expert non fa lavoro meccanico qui: interviene solo per validare che il dataset sia rappresentativo — che copra le situazioni reali, che i profili utente abbiano senso, che gli scenari siano plausibili.
Un approccio consolidato è strutturare il dataset lungo tre assi:
- Features: le funzionalità specifiche del prodotto che il sistema deve gestire
- Scenarios: le situazioni che il sistema deve affrontare — richiesta ambigua, nessun risultato trovato, dati non validi, utente frustrato
- Personas: i profili utente con caratteristiche e aspettative diverse
L'esperto non costruisce questo dataset da zero. Lo convalida — e quella validazione è il suo contributo ad alto valore.
Fase 3 – Pass or fail
Questo è il momento di contributo massimo. Per ogni interazione nel dataset, il domain expert fa due cose — e solo due.
Giudizio binario: passa o fallisce. Nessuna scala 1-5, nessun voto su dimensioni multiple. Solo: "questo ha raggiunto l'obiettivo o no?".
Hamel Husain, machine learning engineer, che ha lavorato su sistemi di evaluation in oltre trenta aziende, è categorico sul punto: i sistemi di scoring numerici non funzionano perché non sono azionabili — cosa significa migliorare da 3 a 4? — non si correlano con ciò che conta davvero per l'utente, e incoraggiano la proliferazione di metriche che sembrano precise ma non lo sono. Il binario non è una semplificazione: è una scelta metodologica più onesta.
Critica dettagliata. La critica deve giustificare il giudizio con sufficiente ricchezza da permettere a chiunque legga il dataset in futuro di capire il ragionamento — cosa ha funzionato o cosa ha mancato, la differenza tra un errore critico e uno minore, le aspettative implicite che la risposta avrebbe dovuto soddisfare.
Un esempio di critica ben scritta per un fallimento:
"Il sistema ha recuperato informazioni sul formato corretto dei numeri d'ordine e ha identificato che l'utente è nuovo, ma non ha incluso nessuna di queste informazioni nella risposta. Il messaggio finale è generico e non educativo — fallisce perché non sfrutta il contesto disponibile per aiutare l'utente."
Un esempio per un passaggio nonostante imperfezioni:
"Il sistema ha completato correttamente la prenotazione e dato il numero di conferma — obiettivo primario raggiunto. Non ha chiesto preferenze di posto o esigenze alimentari, che sarebbe stato meglio, ma il fallimento nell'obiettivo principale è assente, quindi passa."
Quanti esempi? Una buona euristica: parti da circa 30 e continua finché non smetti di vedere nuovi tipi di fallimento. Non "ho abbastanza dati" — ma "non sto imparando nulla di nuovo".
Fase 4 – Calibrare il judge
Una volta costruito il judge LLM, il domain expert valida periodicamente i suoi giudizi su campioni rappresentativi.
Nel progetto Honeycomb, bastarono tre iterazioni per raggiungere un accordo superiore al 90% tra il judge e Phillip Carter, l'esperto di dominio. C'è un effetto collaterale che pochi si aspettano. Carter raccontò che vedere come l'LLM scomponeva il ragionamento lo aiutò a rendersi conto di non essere coerente nel giudicare certi edge case.
Il judge non diventa solo uno strumento di automazione — diventa uno specchio che rende esplicita la conoscenza tacita, incluse le sue contraddizioni interne.
🔗Sitografia
2015
[0] Dan Snierson , Silicon Valley recap: Binding Arbitration, EW, 10/06/2015
2017
[0] Sam Byford, The hot dog-identifying app from HBO’s Silicon Valley is real, and you can download it now, TheVerge, 14/05/2017
[1] Timothy J. Seppala , The ridiculous Not Hotdog app from 'Silicon Valley' is real, Engadget, 15/05/2017
2018
[0] Juan Jesús Velasco, Lo mejor de 'Silicon Valley' es que las fases de una startup se parecen a lo que cuentan. Lo peor también es eso, Xataka, 19/04/2018
2023
[0] Amanda Hoover, Suspenden chatbot de trastornos alimentarios en EE UU por dar consejos dañinos, Wired, 01/06/2023
[1] Kate Wells, What Does a Chatbot Know About Eating Disorders? Users of a Help Line Are About to Find Out, KFF Health News, 12/06/2023
[2] Lance Eliot, Key Lessons Involving Generative AI Mental Health Apps Via That Eating Disorders Chatbot Tessa Which Went Off The Rails And Was Abruptly Shutdown, Forbes, 13/12/2023