¡Parceros, AWS User Group Medellín è geniale!


Di recente ho partecipato per la prima volta a un meetup dell’AWS User Group presso la Universidad EAFIT di Medellín, ospitato questa volta nel Blocco 38. Non avevo idea di quanto fosse vasto il campus — tanto da ritrovarmi, senza volerlo, a entrare dalla porta sbagliata, quella riservata alle auto.
Dopo pochi passi, una guardia di sicurezza mi ha notato e si è avvicinata con passo deciso per farmi presente, con cortesia ma senza troppi giri di parole, che avrei dovuto uscire e rientrare dall’ingresso corretto. Un piccolo fuori programma che ha reso l’inizio della giornata un po’ più movimentato del previsto — e mi ha fatto realizzare che avrei potuto semplicemente consultare la mappa interattiva per capire dove mi avrebbe lasciato l’Uber.
¡Parceros, AWS User Group Medellín es genial!
La sessione, guidata da Santiago García, Solutions Architect di AWS, era incentrata su "Lo Nuevo de la Inteligencia Artificial Generativa con AWS. Agentes, S2S, MCPs, y más" e mi ha offerto uno sguardo chiaro e concreto sia sul presente che sul futuro della generative AI.
Santiago ha aperto condividendo due dati dal report di Gartner che mi hanno particolarmente colpito. Entro il 2028, si stima che un terzo dei software aziendali includerà intelligenza artificiale basata su agenti — oggi siamo appena all’1%. E non solo: il 15% delle decisioni aziendali sarà preso con l'aiuto dell'intelligenza artificiale.

Questi dati suggeriscono che la GenAI sta gradualmente diventando una componente strutturale nei processi aziendali, con implicazioni sempre più concrete sul nostro modo di lavorare e prendere decisioni.
Basti pensare a un caso semplice come l’automatizzazione nella scrittura dei report. Oggi è possibile caricare un foglio Excel con dati grezzi e ottenere, in pochi secondi, una sintesi testuale coerente, completa di analisi e suggerimenti, pronta per essere inviata a colleghi o clienti. Un’attività che un tempo richiedeva ore, oggi si può risolvere con pochi passaggi e qualche centinaio di token.
Unità di base: Tokens
Come ha spiegato Santiago, ogni testo elaborato da un LLM viene suddiviso in unità chiamate token. Questi possono corrispondere a parole intere, frammenti di parole o segni di punteggiatura. In media, una parola genera circa 1,3 token.
Questo dettaglio è rilevante perché il costo dell’utilizzo dei modelli linguistici si basa sul numero totale di token elaborati, sia in ingresso (ciò che viene richiesto) sia in uscita (la risposta del modello). Conoscerne il funzionamento permette di scrivere prompt più efficienti e di gestire con maggiore consapevolezza le risorse impiegate.

Un esempio molto efficace — e anche piuttosto divertente — mostrato durante il meetup ha reso il concetto ancora più chiaro. La frase “¡Parceros, AWS User Group Medellín es genial!” contiene 46 caratteri, ma viene suddivisa in 13 token. Come si vede nell’immagine, ogni parola (o parte di parola) viene codificata in modo indipendente, e anche la punteggiatura viene trattata come un token a sé stante.
In Colombia, parceros è un termine informale e molto usato per dire “amici” o “compagni” — una parola tipica del linguaggio quotidiano a Medellín e in altre zone del paese. La frase usata come esempio, quindi, è anche un saluto amichevole rivolto ai partecipanti del meetup AWS.

RAG: La soluzione per utilizzare i propri dati
Altro aspetto interessante emerso durante il talk è che una delle sfide più grandi è come far sì che un modello risponda a domande usando le informazioni aziendali (documenti, manuali, ecc.) senza che diventi eccessivamente costoso e lento. Come risolvere il problema? La "buena noticia" è che esiste una soluzione, ed è la RAG (Retrieval Augmented Generation).
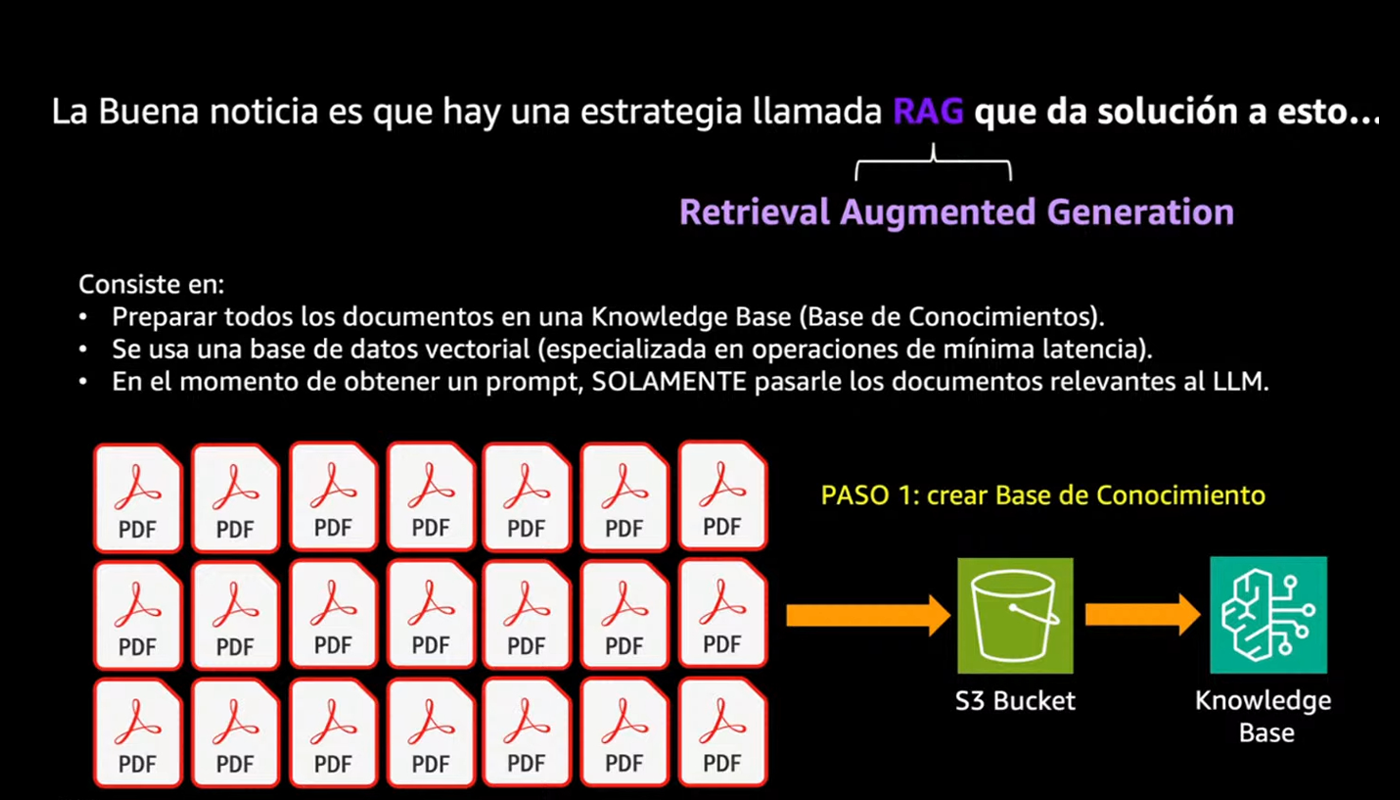
A questo punto del talk, una delle parti più interessanti è stata scoprire quanto sia semplice iniziare a costruire una soluzione basata su RAG, anche senza scrivere una riga di codice. Santiago ci ha mostrato un esempio pratico utilizzando i servizi di AWS: è sufficiente caricare i propri documenti — ad esempio file PDF o Word — in un bucket Amazon S3. Da lì, tramite l’interfaccia web di Amazon Bedrock, è possibile attivare una funzione chiamata knowledge bases, che automatizza l’intero processo. Il servizio si collega al bucket S3, esegue la vettorializzazione dei documenti e li rende immediatamente interrogabili attraverso modelli generativi.
Per quanto riguarda lo storage dei vettori, AWS offre diverse opzioni, tra cui OpenSearch Serverless e il nuovo S3 Vectors. Secondo Santiago, proprio quest’ultimo rappresenta una vera svolta: consente di memorizzare vettori direttamente in S3, in modo nativo, con un risparmio fino al 90% rispetto alle soluzioni tradizionali.
Agenti intelligenti
Se chiedi "cosa fare questo sabato a Medellín?" ad un modello linguistico tradizionale, sicuramente ti suggerirà qualcosa basandosi esclusivamente su ciò che ha appreso durante l’addestramento. Ti dirà, ad esempio, di visitare la Piedra del Peñol — anche se magari sta piovendo o l’evento che cita è finito anni fa. Non ha accesso al presente, né alla realtà contingente. Come è stato ben spiegato durante il meetup, la vera rivoluzione non è nei modelli sempre più grandi, ma nella loro capacità di compiere azioni concrete e contestuali.
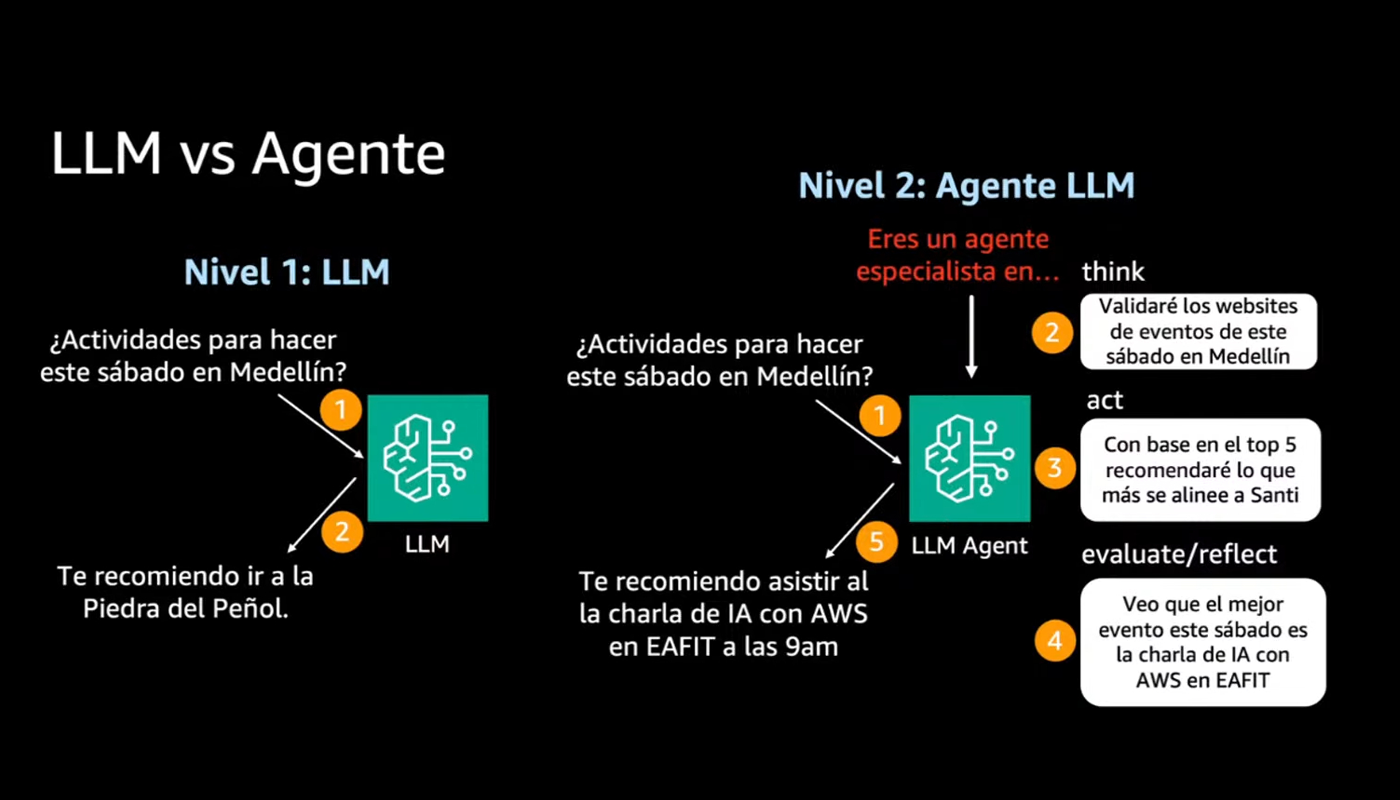
Un agente intelligente, invece, parte da quella stessa domanda, ma la affronta in modo completamente diverso. Prima di rispondere, può: consultare in tempo reale siti web con gli eventi in programma, controllare le previsioni meteo aggiornate, interrogare database locali e fornire suggerimenti contestuali e pertinenti. In altre parole, non si limita a restituire un’informazione: agisce, verifica, incrocia dati e poi risponde. È il passaggio da informazione statica a intelligenza operativa.
Le capacità che fanno la differenza
Santiago ha descritto quattro caratteristiche fondamentali che rendono questi agenti qualcosa di ben diverso rispetto alle soluzioni più semplici.
La prima riguarda la possibilità di accedere a dati in tempo reale. Un agente può interrogare API esterne, consultare database aziendali o pubblici e aggiornare le proprie risposte in base a ciò che sta accadendo nel momento stesso in cui riceve la richiesta, superando così il limite imposto dal cutoff dell’addestramento.
La seconda caratteristica è l’integrazione con strumenti, come i tools e gli action groups offerti da AWS Bedrock. Grazie a questi, un agente è in grado di eseguire operazioni, manipolare dati, attivare processi e dialogare con altri sistemi. È come se acquisisse delle mani digitali, capaci di interagire attivamente con l’ambiente.
Un altro elemento chiave è la memoria persistente. A differenza dei modelli più semplici, che dimenticano tutto tra un’interazione e l’altra, gli agenti sono in grado di mantenere il contesto nel tempo. Questo consente conversazioni più continue, coerenti e personalizzabili, soprattutto in ambiti dove il dialogo con l’utente si sviluppa in più fasi. Infine, c’è la capacità di agire in autonomia.
Gli agenti non si limitano a rispondere a una domanda, ma possono ragionare, pianificare e decidere seguendo un percorso logico interno, spesso strutturato come una "chain of thought" (COT).
Il caso di "Pepe", il ristorante colombiano
A chiusura di una breve introduzione sulla RAG, Santiago ha mostrato un esempio concreto che ha reso tutto ancora più chiaro: la creazione in tempo reale di un agente intelligente per un ristorante colombiano immaginario chiamato “Pepe”.
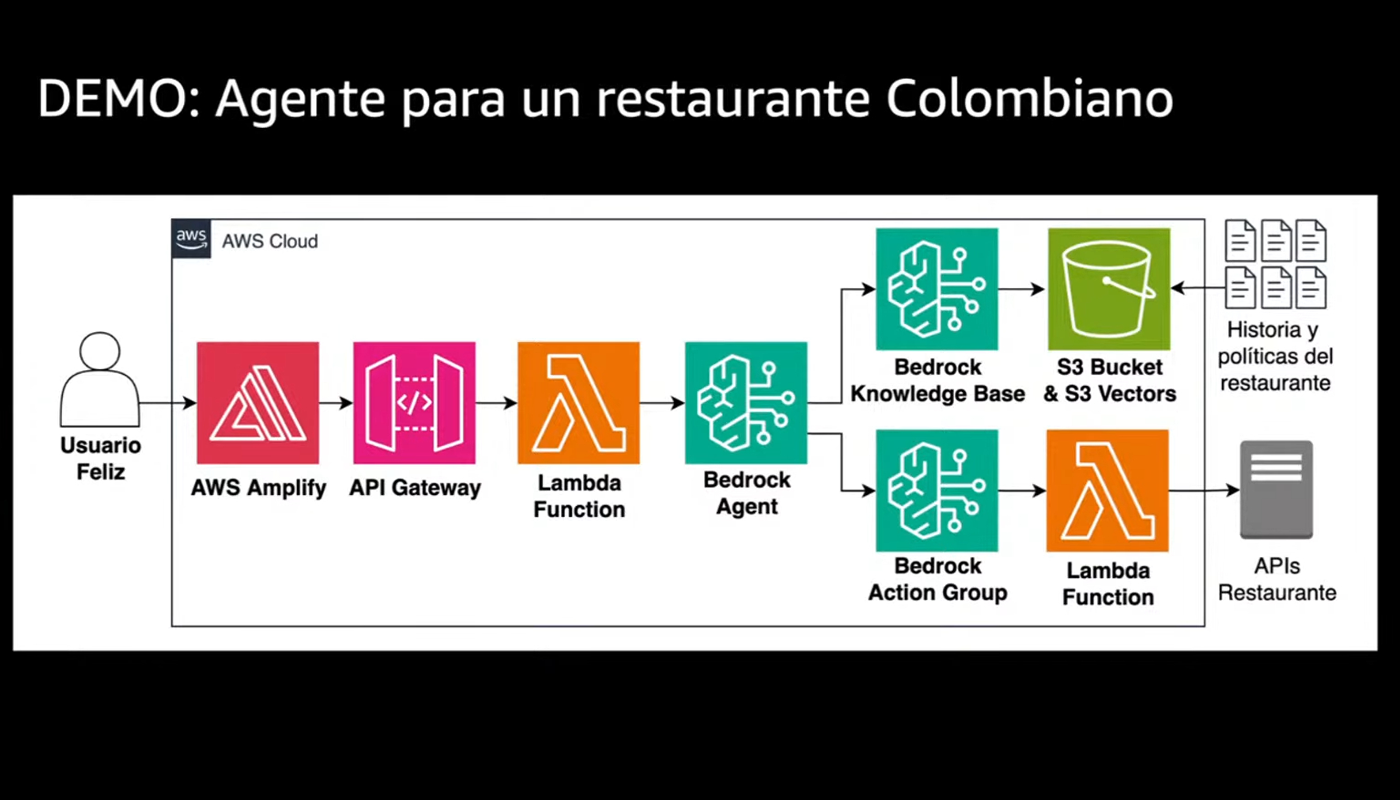
In pochi minuti, questo agente era in grado di accedere a un’API per recuperare il menù aggiornato, rispondere in linguaggio naturale con una personalità definita nel prompt, mantenere il contesto della conversazione con i clienti.
MCP: una porta USB-C per le applicazioni di AI
Un altro tema che ha catturato la mia attenzione è stato il Model Context Protocol (MCP). Santiago lo ha presentato come una tecnologia promettente, introdotta da Anthropic, che potrebbe cambiare in modo significativo il modo in cui gli agenti interagiscono con strumenti e servizi esterni.

Chi ha lavorato con sistemi distribuiti conosce bene il tipo di problema che MCP cerca di risolvere: ogni team adotta soluzioni proprie, segue approcci diversi e sviluppa agenti spesso tra loro incompatibili. Il team dati, per esempio, può costruire un agente che comunica tramite API REST, utilizzando una struttura proprietaria ben documentata. Allo stesso tempo, il team di innovazione può sviluppare qualcosa di completamente diverso, con protocolli alternativi e convenzioni personalizzate.
Il risultato è un ecosistema frammentato, in cui ogni agente parla un linguaggio differente. Quando arriva il momento di farli dialogare o di trasferire conoscenza tra i team, emergono incompatibilità che spesso rendono necessario ricominciare da capo. Ed è proprio qui che entra in gioco MCP. Proprio come lo standard USB-C ha eliminato la confusione dei vecchi cavi proprietari, MCP propone un approccio unificato e riutilizzabile.
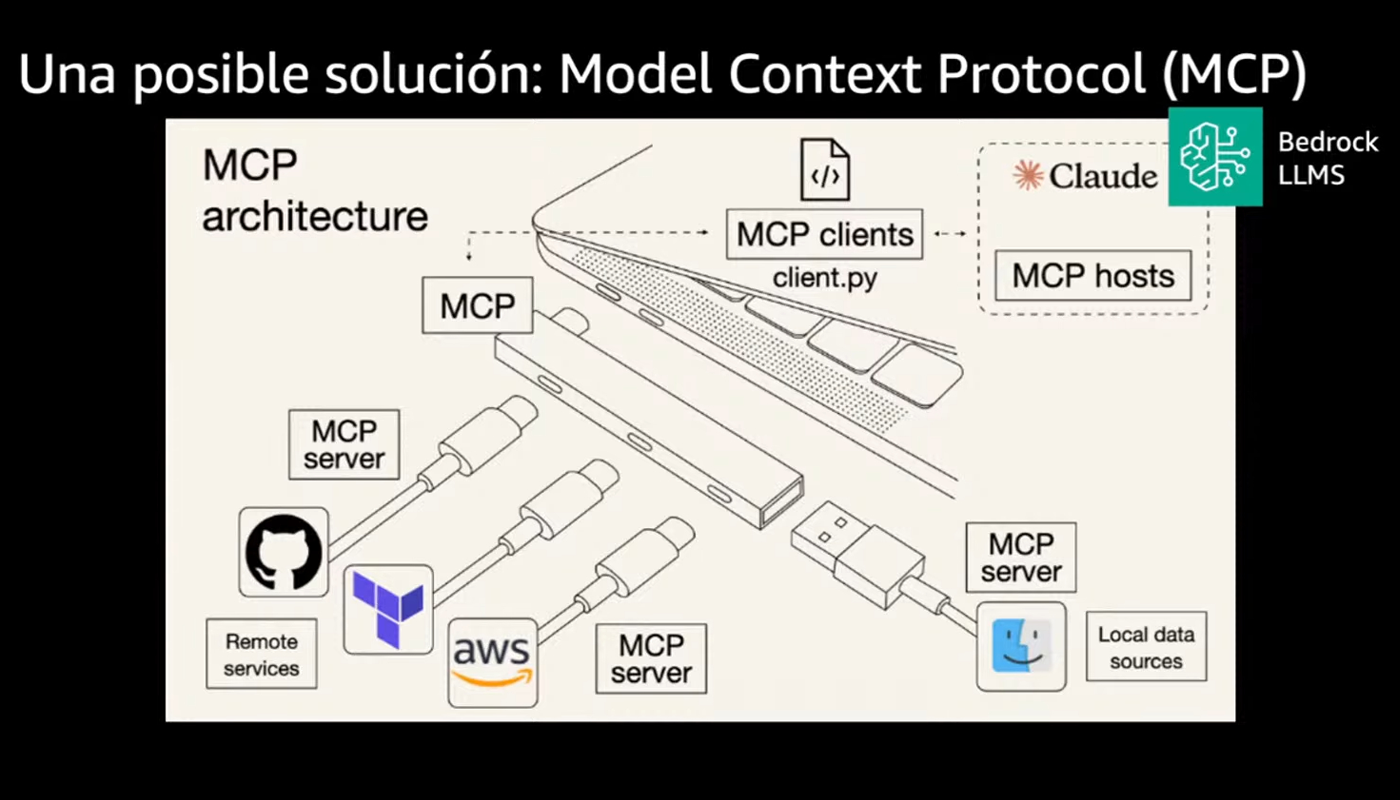
Il protocollo definisce un’architettura client-server chiara, in cui qualsiasi client compatibile può comunicare con qualsiasi server MCP, indipendentemente dalla tecnologia sottostante. Invece di costruire integrazioni su misura per ogni combinazione possibile, diventa finalmente possibile collegare modelli, strumenti e sistemi attraverso un linguaggio comune.
AWS MCP
Durante la dimostrazione, García ha mostrato l’ampiezza dell’ecosistema MCP, evidenziando come AWS lo supporti già per servizi come DynamoDB, S3, CDK, CloudFormation e Terraform, coprendo così l’intero stack di sviluppo cloud. Ma l’ecosistema si estende ben oltre i confini di AWS: GitHub viene utilizzato per la gestione dei repository e l’automazione DevOps, Slack per la comunicazione interna e la gestione degli alert, Figma per il design e la prototipazione, e Draw.io per la generazione automatica di diagrammi architetturali.

García ha sottolineato un caso d’uso particolarmente interessante: "Immaginate di arrivare a un incidente e dover capire rapidamente l’architettura. Passate i file sorgente all’agente e, in due minuti, avete sia la spiegazione del codice che un diagramma architetturale automatico".
Real-Time Voice AI
no, aspetta, volevo dire un’altra cosa.
Stiamo entrando in una nuova fase dell'interazione uomo-macchina (HCI) — in cui l’AI non solo comprende le nostre parole, ma risponde all’istante con una voce umana. Questa è una delle novità più interessanti presentate da Santiago.
Amazon Nova Sonic è un modello speech-to-speech (STS) disponibile su Amazon Bedrock che permette di creare esperienze vocali in tempo reale segnando un vero cambio di paradigma nell’interazione vocale.
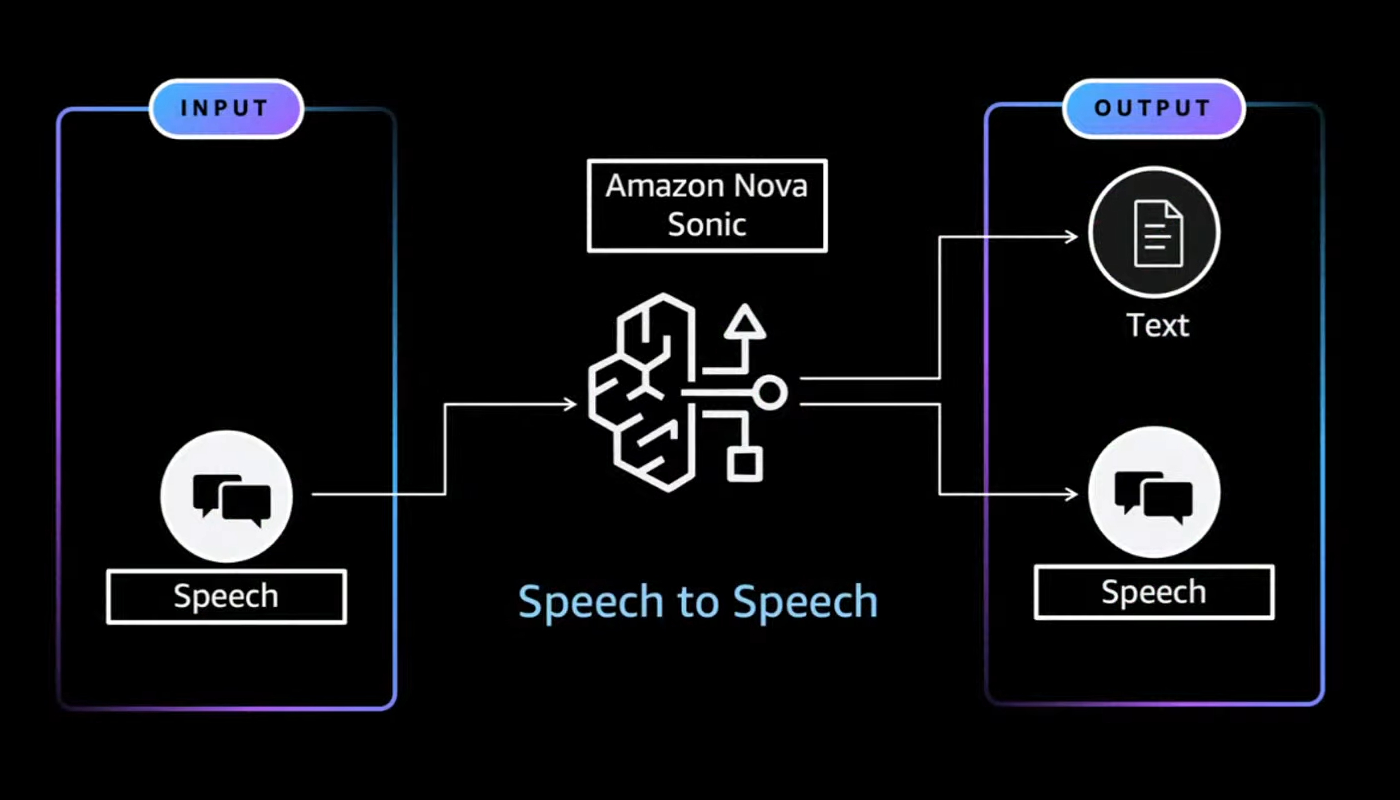
Ricordo bene com’era, fino a poco tempo fa, comunicare con un agente vocale: una pipeline lunga e poco naturale, in cui l’audio veniva prima convertito in testo (speech-to-text, STT), poi elaborato da un modello linguistico, e infine riconvertito in audio (text-to-speech, TTS). Un processo che, oltre a risultare costoso, introduceva una latenza tale da compromettere la fluidità della conversazione.
Nova Sonic ribalta completamente questo approccio, offrendo una comunicazione diretta da audio ad audio, con una latenza media di appena 1,09 secondi. Ma ciò che colpisce davvero è la possibilità di interrompere l’agente mentre sta parlando, proprio come faremmo in una conversazione reale.
Durante una demo realizzata in precedenza dalla community di AWS Medellín, Santiago ha mostrato come basti un “no, aspetta, volevo dire un’altra cosa” per ottenere una reazione immediata. Finalmente, niente più pause innaturali in attesa che l’AI completi la sua risposta.
Sicurezza AI-native
Un altro aspetto che ha attirato la mia attenzione è stato l’approccio alla sicurezza, pensato specificamente per ambienti AI. Bedrock Guardrails introduce un livello di protezione pensato per i LLM, andando ben oltre i classici Web Application Firewall. Questi strumenti, per quanto fondamentali, non comprendono la logica del linguaggio naturale.
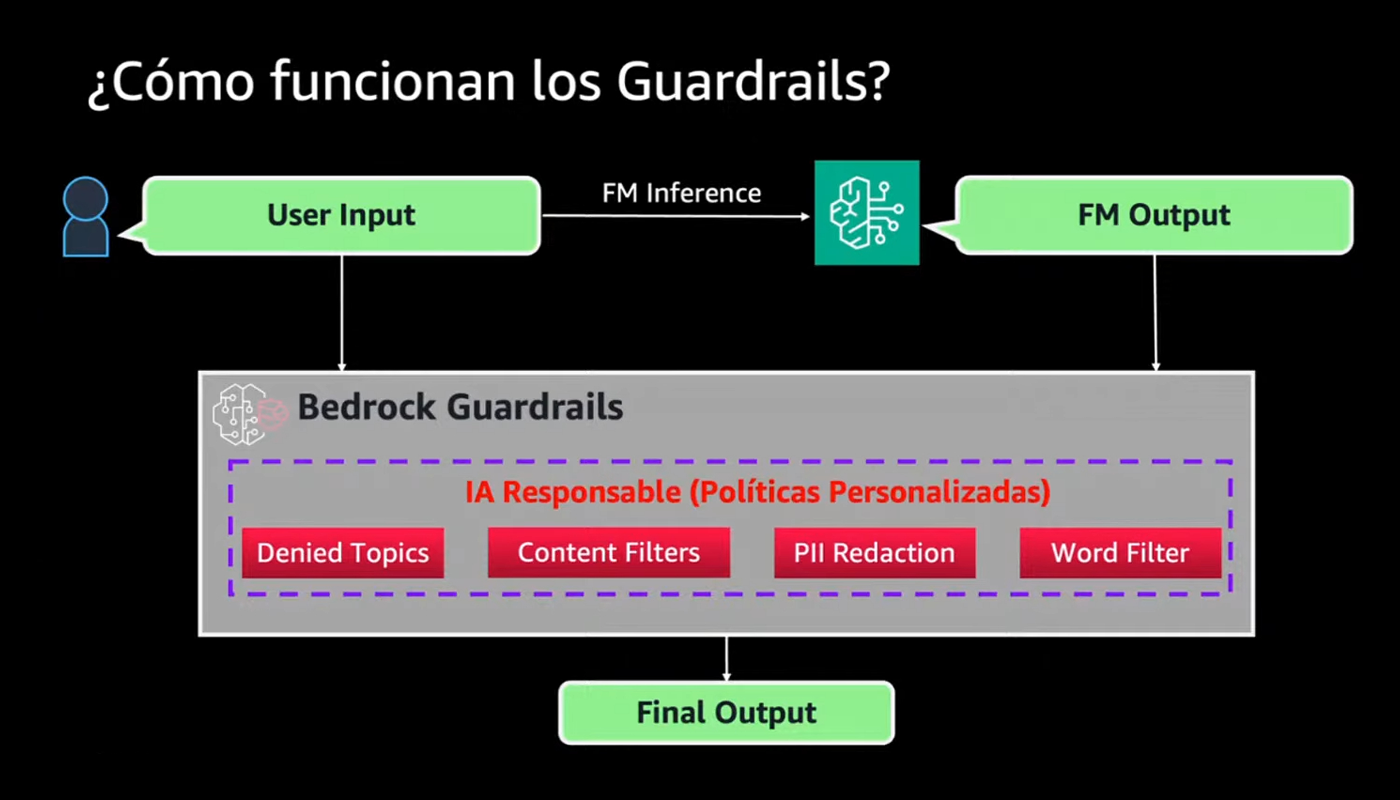
Guardrails agisce come un doppio filtro, analizzando sia gli input sia gli output dei modelli. È in grado di riconoscere tentativi di prompt injection, fughe di dati sensibili o violazioni delle policy aziendali.
Santiago, riprendendo l'esempio del ristorante colombiano, ha fatto un esempio concreto: "se l’agente di un ristorante riceve una domanda sulla concorrenza, il sistema blocca la risposta automaticamente, mantenendo il focus sul ruolo specifico dell’agente".
OWASP
L’adozione degli OWASP for LLMs segna un momento di maturazione del settore. Così come l’OWASP Top 10 ha definito per anni le vulnerabilità critiche delle applicazioni web, la nuova versione per i modelli linguistici individua i principali rischi legati all’AI generativa.

Santiago ha sottolineato quanto sia importante integrare questi standard già in fase di progettazione, e non come correzione a posteriori. Un consiglio che riflette l’esperienza di chi ha visto progetti fallire per avere sottovalutato la sicurezza troppo tardi.
Oltre il POC: scalare l’AI in azienda
Tra gli annunci più significativi emersi sia durante il meetup che dal keynote dell’AWS Summit di New York 2025, spicca Agent Core, presentato appena pochi giorni prima dell’evento all’università EAFIT. Santiago ne ha sottolineato l'importanza, ma è stato Swami Sivasubramanian, vice president for AI and Data di AWS, a delinearne da New York la visione strategica complessiva.
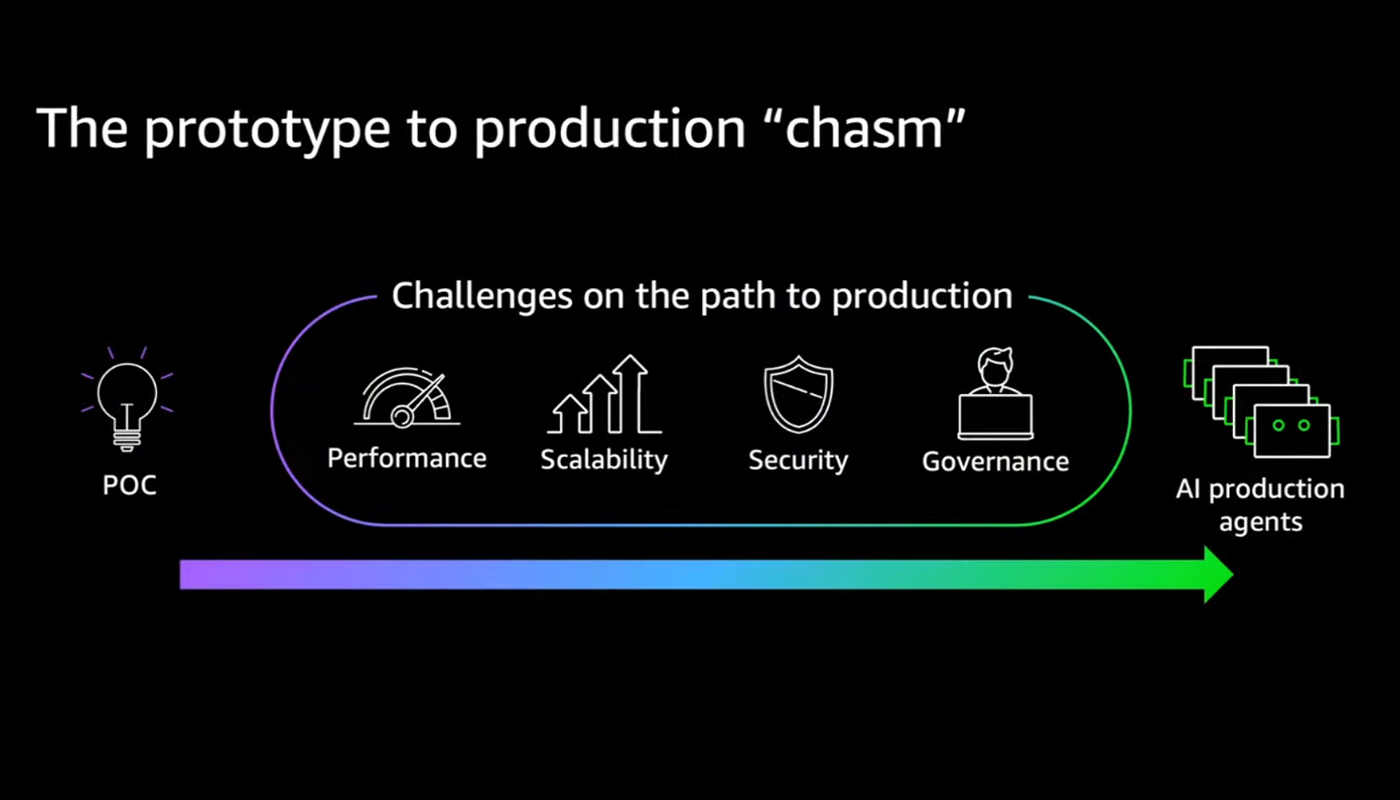
Come ha osservato García, oggi il vero ostacolo all’adozione dell’AI in azienda non è più la realizzazione di un proof of concept. Con Bedrock, creare un agente funzionante è questione di minuti. La sfida emerge quando si cerca di scalare: portare in produzione centinaia o migliaia di agenti richiede requisiti stringenti di sicurezza, governance e interoperabilità. Swami è stato netto nel keynote: “All this muck is slowing down customers and preventing them from getting agents into production quickly”.
Agent Core
È proprio per affrontare questa complessità che nasce Agent Core: un ecosistema modulare pensato per rispondere a tutte le esigenze dell’AI agentica a livello aziendale. Cuore dell’architettura è un runtime serverless capace di eseguire sessioni prolungate fino a otto ore (AgentCore Runtime), con isolamento completo per ogni interazione e meccanismi di recovery automatico. Ma un agente che opera in ambienti complessi ha bisogno di più del solo calcolo. Ha bisogno di memoria — e qui entra in gioco una componente ispirata al funzionamento cognitivo della memoria umana (AgentCore Memory). Santiago l’aveva spiegata con ironia: “È come quando vai in cucina, apri il frigo e non ricordi perché sei lì”.
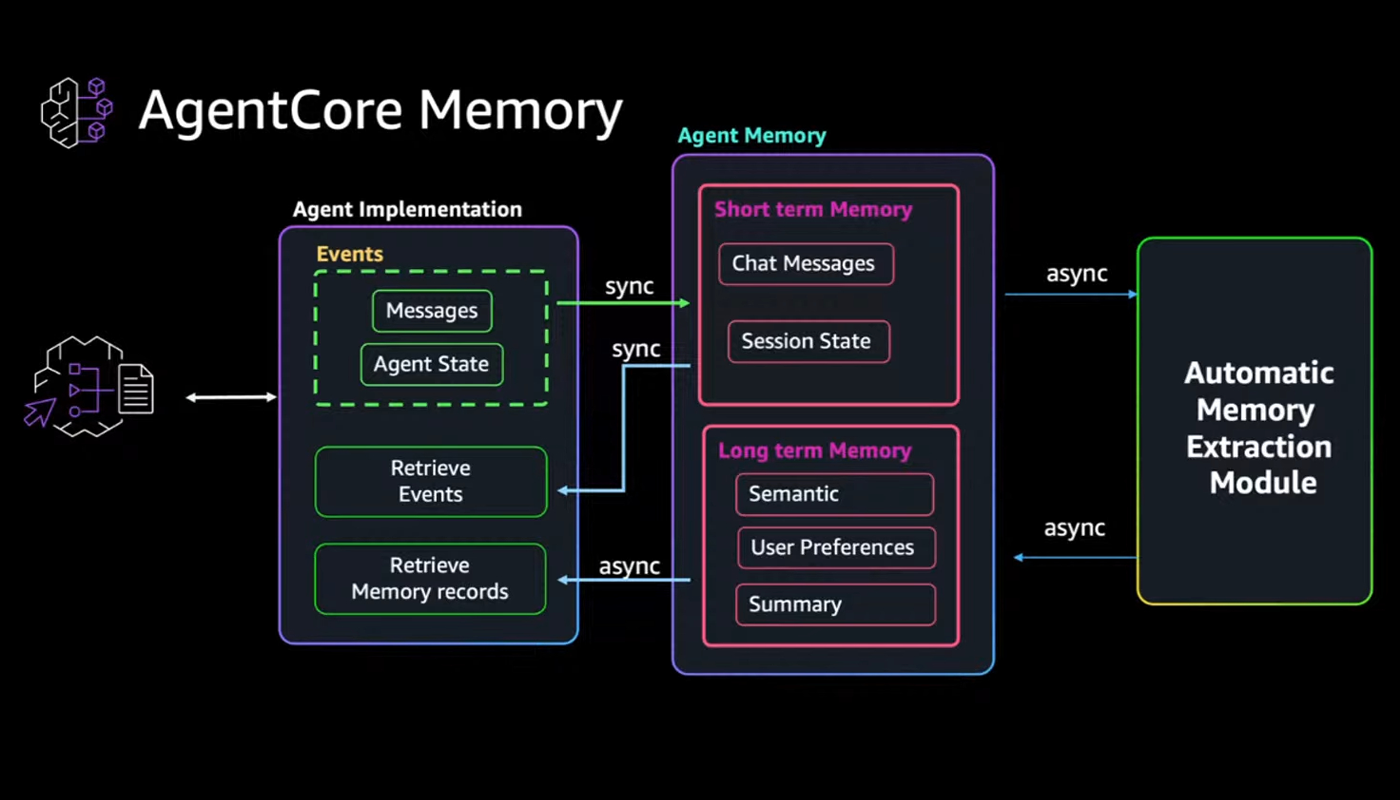
La memoria di Agent Core combina ricordi brevi (short term memory), dettagliati ma volatili, con una memoria a lungo termine (long term memory) più astratta ma duratura, capace di evolvere nel tempo e conservare ciò che conta davvero. Altro nodo critico risolto è quello dell’autenticazione e dell’autorizzazione (AgentCore Identity). Che sia uno sviluppatore con permessi limitati o un’amministratrice con privilegi completi, l’accesso alle risorse è sempre sotto controllo.
Nel quotidiano, gli agenti devono spesso scrivere codice, navigare il web o interagire con strumenti aziendali. Agent Core lo permette con naturalezza: da una sandbox sicura in cui eseguire script complessi (AgentCore Code Interpreter), a un browser cloud veloce e isolato, pronto per affrontare task reali con standard di sicurezza enterprise (AgentCore Browser Tool).
Il collegamento con l’ecosistema MCP è reso semplice da un gateway che consente di trasformare API esistenti in strumenti utilizzabili dagli agenti con pochissime righe di configurazione (AgentCore Gateway).
Il tutto è monitorabile con metriche, debug, tracciamento dettagliato e integrazione con CloudWatch e OpenTelemetry, per non perdere mai di vista ciò che accade dietro le quinte (AgentCore Observability).
Durante il keynote, AWS ha annunciato un investimento di oltre 100 milioni di dollari per lo sviluppo di Agent Core, a conferma che non si tratta di una semplice iniziativa sperimentale, ma della nuova base tecnologica su cui costruire il futuro dell’AI in azienda.
Dal meetup al CLI
Affamato dopo una mattinata intensa — il meetup era iniziato alle 9 e si era concluso verso mezzogiorno — mi sono fermato al centro commerciale Oviedo, a pochi passi dall’università, per concedermi un palito de queso campesino e un momento di pausa. Il pastel era ricco e ben dorato, e la señora al banco mi ha trattato con una gentilezza tutta paisa. Propina doverosa.

Uscendo dall’università EAFIT, avevo la sensazione di aver partecipato a un incontro tecnico solido e ben organizzato, lontano dai facili entusiasmi sull’intelligenza artificiale.
Il meetup dell’AWS UG Medellín si è rivelato un’occasione concreta per osservare da vicino l’evoluzione dell’AI nel contesto aziendale. Quello che avrebbe potuto essere un semplice sabato di formazione si è trasformato in uno spazio orientato alla pratica, arricchito da numerose demo live.
Le previsioni sulla diffusione degli agenti aziendali nei prossimi anni mi sono apparse realistiche, alla luce delle soluzioni illustrate. Non si è parlato di scenari futuristici, ma di strumenti già disponibili — accessibili, volendo, anche oggi stesso dalla CLI di AWS.