
Gli stati alterati di coscienza da sempre hanno affascinato l’umanità, trovando espressione attraverso vari mezzi artistici e culturali. Da antiche tradizioni e rituali sciamanici a sperimentazioni psichedeliche nell’era moderna, ogni epoca ha esplorato queste profondità della psiche umana in modi unici. Uno degli esempi più recenti di questa esplorazione è DeepDream che fonde l’intelligenza artificiale (IA) con estetiche che evocano le visioni psichedeliche di Timothy Leary (1920-1966) e il surrealismo onirico di Salvador Dalì (1904-1989).
Paura e delirio a Zurigo
Steven Levy, giornalista e scrittore per Wired, ci racconta come Alexander Mordvintsev, un computer scientist che si era trasferito da San Pietroburgo a Zurigo per lavorare a Google, fu svegliato nel cuore della notte del 18 maggio del 2015, da un incubo che coinvolgeva la presenza di un intruso nel suo appartamento. Nonostante fosse notte e dopo aver verificato che la moglie e il erano al sicuro, la mente di Mordvintsev era troppo attiva per tornare a dormire.
Come apprendono le macchine?
Approfittando di una politica di Google nota come “20% time”, che incoraggia i dipendenti a dedicare una parte del loro tempo di lavoro a progetti personali che li appassionano, anche se non sono direttamente legati alle loro responsabilità lavorative principali. Così, in quelle ore silenziose, Mordvintsev iniziò a scrivere codice, mosso da una domanda che lo intrigava profondamente: perché le reti neurali artificiali sono così efficienti e cosa avviene esattamente all’interno di queste complesse strutture? Questa indagine non era solo un passatempo, era un desiderio di sondare i misteri nascosti dietro le capacità delle macchine di apprendere e vedere.
Le macchine non vedono un gatto o un cane, come noi, ma un insieme di numeri ed ogni immagine è suddivisa in pixel. Ogni pixel è rappresentato da numeri che ne indicano il canale (rosso, verde e blu) e la sua posizione.

Levy descrive come la curiosità di Mordvintsev lo guidasse attraverso una notte di programmazione e scoperte, che alla fine avrebbe condotto alla creazione di immagini straordinarie e surreali, prodotte manipolando le reti neurali. Queste immagini, note per la loro somiglianza con le visioni psichedeliche e i paesaggi onirici, non erano solo belle; erano una rappresentazione visiva di ciò che accade all’interno delle reti neurali, in particolare di una loro tipologia nota come “Convolutional Networks” (CNNs).
Convolutional Networks
Queste reti neurali guadagnarono notorietà nel 2012, quando AlexNet trionfò nella competizione di computer vision ImageNet. Seguendo questa vittoria, l’architettura di AlexNet, una creazione di Alex Krizhevsky, Ilya Sutskever e Geoffrey Hinton, ha dato forma e ispirazione per lo sviluppo di future architetture di CNNs. In termini generali, l’architettura di una CNN si articola in due parti principali: una dedicata all’estrazione delle features, posizionata nella parte iniziale, e una successiva, che funge da classificatore.
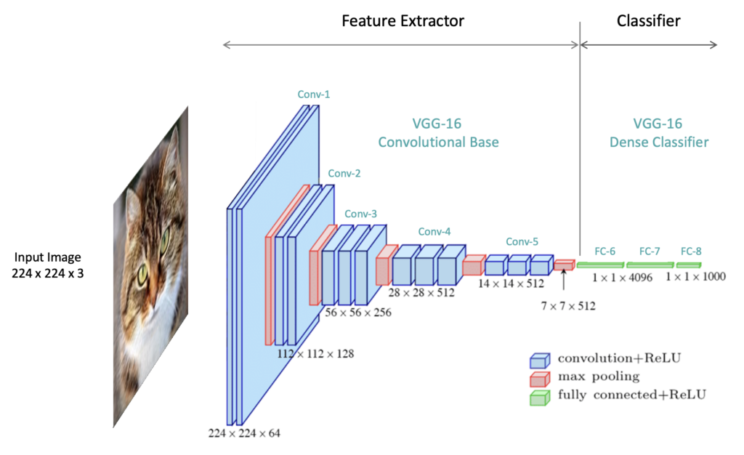
Feature extractor
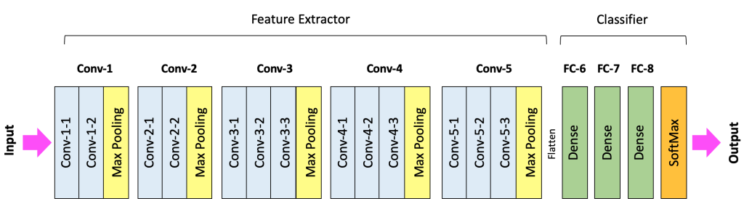
Analizzando il modello VGG-16, ideato da K. Simonyan e A. Zisserman dell’Università di Oxford e noto anche come VGGNet, possiamo osservare come esso si articoli attraverso l’integrazione di cinque blocchi convoluzionali, identificati come Conv-1 fino a Conv-5, che compongono il nucleo dell’estrattore di features. Una configurazione tipica di un blocco convoluzionale è ad esempio quella di uno o più filtri convoluzionali (Conv-1-1, Conv-2-2) seguiti da uno di Max Pooling. Possiamo quindi immaginare una convolution come un filtro che passa su un’immagine, la elabora estraendo features come bordi, contorni, texture, etc.
Adesso utilizzando poche righe di codice in Python diamo un breve sguardo sull’architettura della rete VGG16 implementata da Pytorch creandone un’istanza, inizializzando la rete network con pesi casuali.
|
1 2 3 4 5 6 |
from torchvision import models network = models.vgg16() layers = list(network.features.children()) for layer in layers: print(layer) |
Con .children() iteriamo nei layers convoluzionali, prendendo però solo il primo come esempio possiamo notare che abbiamo come input i 3 canali RGB (Red, Green, Blue) dell’immagine.
|
1 |
Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) |
Questo primo layer produce 64 mappe di features utilizzando un kernel di dimensione 3×3. La stride e il padding sono entrambi impostati su 1, il che significa che il filtro si sposta di un pixel alla volta e che vengono aggiunti dei pixel aggiuntivi intorno all’input per mantenere la dimensione spaziale.
|
1 |
ReLU(inplace=True) |
La Rectified Linear Unit (ReLU) è una funzione di attivazione non lineare che sostituisce tutti i valori negativi con zero, con l’opzione inplace=True questa modifica viene effettuata direttamente sull’input, risparmiando così memoria.
Seguendo questa sequenza (Sequential) , vediamo che l’architettura incrementa il numero di canali (o mappe di features) mentre riduce le dimensioni spaziali attraverso il pooling. Questo è tipico delle architetture convoluzionali: acquisiscono informazioni a basso livello (come i bordi) nei primi layers e costruiscono rappresentazioni più complesse nei layers successivi.
L’implementazione dell’architettura VGG16 di PyTorch risulta così essere composta:
|
1 |
print(network) |
- 2 layers convoluzionali con 64 filtri seguiti da 1 layer di pooling.
- 2 layers convoluzionali con 128 filtri seguiti da 1 layer di pooling.
- 3 layers convoluzionali con 256 filtri seguiti da 1 layer di pooling.
- 3 layers convoluzionali con 512 filtri seguiti da 1 layer di pooling.
- Altri 3 layers convoluzionali con 512 filtri seguiti da 1 layer di pooling finale.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
(features): Sequential( (0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (1): ReLU(inplace=True) (2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (3): ReLU(inplace=True) (4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False) (5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (6): ReLU(inplace=True) (7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (8): ReLU(inplace=True) (9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False) (10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (11): ReLU(inplace=True) (12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (13): ReLU(inplace=True) (14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (15): ReLU(inplace=True) (16): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False) (17): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (18): ReLU(inplace=True) (19): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (20): ReLU(inplace=True) (21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (22): ReLU(inplace=True) (23): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False) (24): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (25): ReLU(inplace=True) (26): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (27): ReLU(inplace=True) (28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (29): ReLU(inplace=True) (30): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False) ) |
Classifier
Dopo l’estrattore segue la sezione dedicata al classificatore, il quale ha il compito di convertire le features rilevate in previsioni di classe nello strato di output finale.
|
1 2 3 4 5 6 7 8 9 |
(classifier): Sequential( (0): Linear(in_features=25088, out_features=4096, bias=True) (1): ReLU(inplace=True) (2): Dropout(p=0.5, inplace=False) (3): Linear(in_features=4096, out_features=4096, bias=True) (4): ReLU(inplace=True) (5): Dropout(p=0.5, inplace=False) (6): Linear(in_features=4096, out_features=1000, bias=True) ) |
È importante notare che VGG-16 è stato istruito utilizzando il dataset ImageNet, composto da 1.000 categorie diverse. Di conseguenza, il layer (6) di output è composto da 1.000 neuroni, ciascuno dei quali esprime la probabilità che l’immagine in ingresso appartenga a una determinata classe.
Trasformiamo così un tensore di dimensione 4096 in un tensore di dimensione 1000.
|
1 |
(6): Linear(in_features=4096, out_features=1000, bias=True) |
La classe che si distingue con la probabilità più elevata viene identificata come quella prevista dall’algoritmo.
Inceptionism
Cosa accadrebbe se prendessimo un’immagine, scegliessimo un filtro convoluzionale e aumentassimo il gradiente sull’immagine di input per massimizzare l’output di quel filtro? Questa era la domanda a cui Mordvintsev stava dando risposta, utilizzando le CNNs per generare immagini oniriche che mostrassero come la rete interpreta i differenti stimoli visivi. Mediante l’impiego del Gradient Ascent (Ascesa del Gradiente), sarebbe così possibile comprendere e visualizzare le features che la rete ha interiorizzato nel corso della sua fase di training.
Questo approccio, denominato network feature visualization, ha acquisito il soprannome di “Inceptionism”. In omaggio a InceptionNet, un’architettura di rete neurale, e al film “Inception”, celebre per i suoi intricati livelli di sogno all’interno del sogno.
Nel 2015, l’articolo “Inceptionism: Going Deeper into Neural Networks” ha evidenziato un esempio significativo legato all’interpretazione dei manubri da parte delle reti neurali. Durante il training, sono emersi dei bias distintivi: la rete mostrava una notevole difficoltà nel riconoscere un manubrio, a meno che non fosse rappresentato insieme a un braccio in atto di sollevarlo.

Tale limitazione può essere attribuita alla mancanza di esempi nel training dataset in cui i manubri fossero presentati indipendentemente da un contesto umano. In questo scenario, l’applicazione di tecniche di visualizzazione delle featues assume un ruolo cruciale perché sarebbe possibile rilevare e analizzare le anomalie o i bias presenti nell’apprendimento della rete, consentendo una maggiore precisione e una comprensione più profonda dei meccanismi interni della CNN.
Come faccio a dormire ora?
Quella notte alle 2:32 am Mordvintsev condivise i risultati sul defunto Google+ aziendale tornando dormire.

Il giorno seguente, Mordvintsev si svegliò per scoprire circa 60 commenti dai suoi colleghi di Google, segnando l’inizio di quello che sarebbe presto diventato un fenomeno virale da twitter alle bacheche di Pinterest.
La scoperta, che in seguito avrebbe preso il nome di “DeepDream”, si diffuse rapidamente online, una crescita stimolata non solo dalla curiosità di Mordvintsev, ma anche dai contributi dei ricercatori Christopher Olah e Mike Tyka.
Sitografia
[0] Alexander Mordvintsev, Christopher Olah,Mike Tyka, Inceptionism: Going Deeper into Neural Networks, Research Blog, 18/06/2015
[1] Alexander Mordvintsev, Christopher Olah,Mike Tyka, DeepDream – a code example for visualizing Neural Networks, Research Blog, 1/07/2015
[2] Jeff Guo, Why Google’s nightmare AI is putting demon puppies everywhere, The Washigton Post, 8/07/2015
[3] John Brownlee, Why Google’s Deep Dream A.I. Hallucinates In Dog Faces, Fast Company, 23/07/2015
[4] Steven Levy, Inside Deep Dreams: How Google Made Its Computers Go Crazy, Wired, 11/12/2015
[5] Olah, Chris and Mordvintsev, Alexander and Schubert, Feature Visualization, Distill, 7/11/2017
[6] Is artificial intelligence set to become art’s next medium?, Christies, 11/12/2018
[7] Naveen Manwani, Deep Dream with TensorFlow: A Practical guide to build your first Deep Dream Experience, Medium, 29/12/2018
[8] Kanon , Alexander Mordvintsev, “deepdream.c”, 2015/2021, Medium, 18/05/2021
[9] Víctor Millán, Así es la regla del 20% de los fundadores de Google que aún sigue usando con éxito la empresa, El Economista, 4/01/2022
Bibliografia
[0] Arthur I. Miller, The Artist in the Machine, The MIT Press, 2020
Papers
VGGNet
[0] Very deep convolutional networks for large-scale image recognition, 2015
AlexNet
[0] ImageNet Classification with Deep Convolutional Neural Networks, 2015
GoogLeNet
[0] Going Deeper with Convolutions , 2015