
Rituales (Circular 74 # 39B-22) è uno dei miei caffè preferiti a Medellìn (Colombia), in una strada residenziale a pochi passi dal parco di Laureles e da altri caffè come Algarabía e Revolución (Calle 37 # 79-32). Anche se accanto all’avenida Nutibara, il coffee-shop è silenzioso e tranquillo, ottimo per lavorare da remoto. Adesso immaginiamo di dover realizzare un chatbot per una bottega del caffè che riceva le ordinazioni del cliente.

All’inizio del processo di annotazione i dati sono privi di una struttura o di un ordine e per loro natura incomprensibili ad una macchina. Per un algoritmo supervisionato i dati senza una label sono rumore.
Fenomeno linguistico
I dati che raccogliamo per creare in training dataset solitamente vengono annotati usando una rappresentazione di dominio, intent e entities.
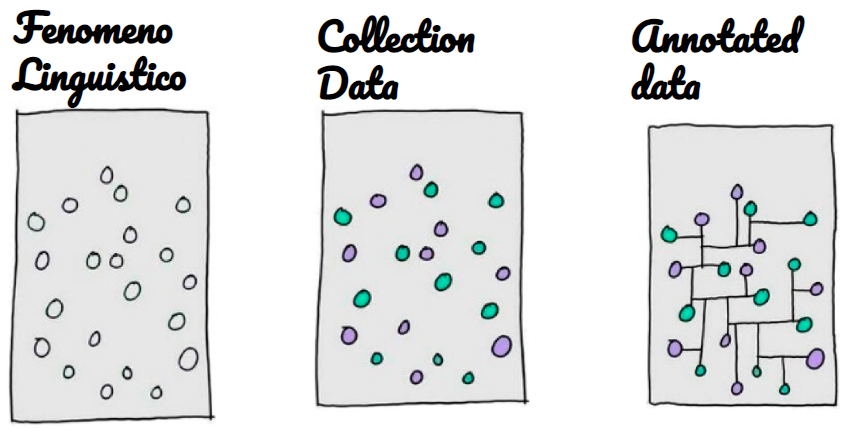
Questa struttura ci aiuta ad analizzare il fenomeno linguistico, il come si esprimono i nostri utenti, non dimenticandoci che un linguaggio troppo ampio può portare più facilmente ad un errore da parte del sistema di riconoscimento, mentre la definizione di un linguaggio troppo stretto rischia di portare all’esclusione di risposte che l’utente potrebbe ragionevolmente fornire.
Per spiegare che cosa si intende per dominio, prendiamo come esempio il coffee-shop Rituales a cui vado spesso a Laureles. Ad esempio la parola affogato senza un dominio potrebbe riferirsi sia alla tipologia del caffé, ma anche ad un tragico evento.
Comprendiamo il contesto delle parole ristretto, macchiato, cappuccino o affogato perché le abbiamo associate al dominio del caffé. Iniziamo definendo un dominio, o anche più di uno, che ci aiuti a definire un perimetro in cui le parole possano acquistare un senso.
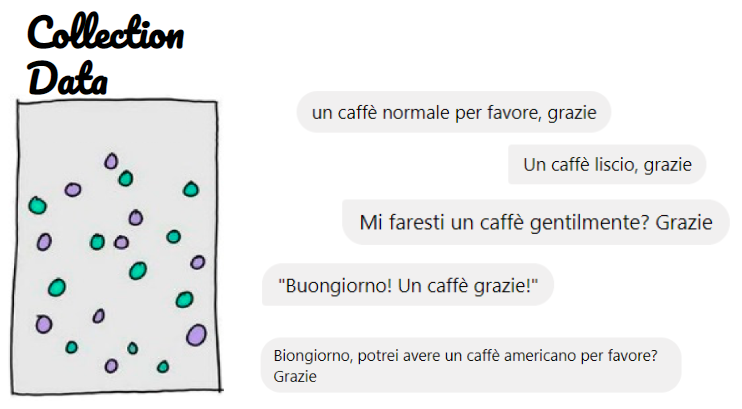
Raccolta dati
L’annotazione linguistica prevede una fase di ricerca etnografica volta a raccogliere le utterances che compongono il fenomeno linguistico che stiamo studiando.
Dobbiamo quindi comprendere come le persone si esprimono nella loro quotidianità in modo da evitare il più possibile bias durante l’annotazione. Ad esempio per l’uomo della strada il bancomat è la vera e propria carta, per l’esperto di dominio come il direttore di banca, l’impiegato è invece lo sportello ATM.
Dobbiamo iniziare a modellare il fenomeno linguistico tramite la raccolta e l’annotazione dei dati. Così facendo il rumore iniziale può essere trasformato in un modello comprensibile alle macchine.
In antropologia la ricerca etnografica consiste nell’esperienza diretta sul campo, attraverso l’osservazione partecipante. Durante la quale l’etnografo raccoglie i suoi dati attraverso i colloqui, la partecipazione alla vita quotidiana o la semplice osservazione.
Bronislaw Malinowski (1884-1942) fu il primo antropologo che per svolgere una ricerca ritenne fondamentale apprendere la lingua e cercare di penetrare nell’universo simbolico e mentale degli indigeni.
Vivere con il popolo, condividerne i pasti e i costumi e, imparare, per quanto possibile a sentire e pensare come loro (…)
Per fortuna ordinare un caffè è un’esperienza comune a tutti e di solito per farmi un’idea del dominio inizio semplicemente chiedendo su messenger o telegram ai miei amici di parlarmi della loro esperienza al bar.
Language annotation
Per ogni progetto è importante creare delle linee guida che si devono concentrare su quali e quanti domini analizzare e sullo sviluppo della tassonomia degli intents e delle entities.
Un esempio iniziale di tassonomia potrebbbe essere quello rappresentata nell’immagine che segue, considerando le azioni come ordinare, comprare che l’utente compie sull’oggetto caffè, azioni che per noi non sono altro che nostri intents. Infine, le entities rappresentano gli oggetti del mondo reale.
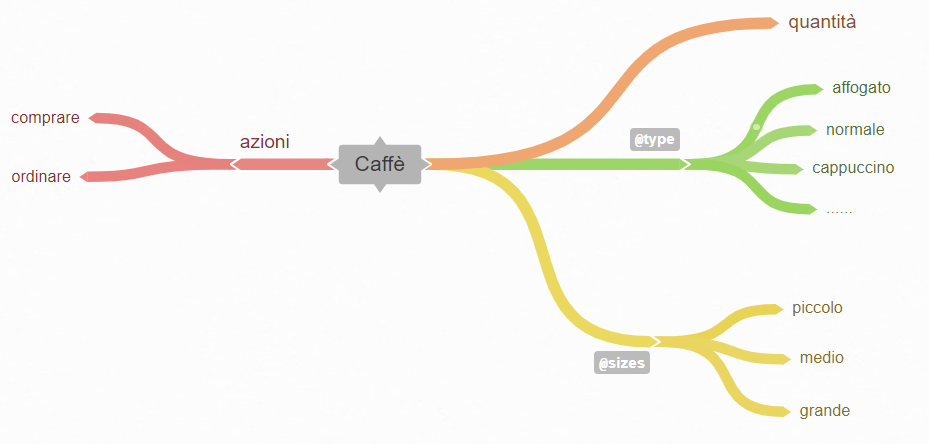
Per gli sviluppatori le entities potrebbero ricordare il concetto di oggetto della programmazione orientata agli oggetti (OOP).
Iniziamo ad annotare
Per iniziare il lavoro di annotazione consideriamo solo gli intents privi di entities, come la seguente frase “mi faresti un caffè” che possiamo ricondurre all’intent #orderCoffee:
#orderCoffee()
|
1 2 |
mi faresti un caffè gentilmente un caffè |
Se prendiamo l’utterance “potrei avere un caffè americano” oltre all’intent di ordinare un caffè riconosciamo che c’è bisogno di un’entity per la tipologia del caffè @type.
#orderCoffee(@type)
|
1 2 |
potrei avere un caffè americano un caffè normale per favore |
Per nuove frasi dovremmo inserire nuove entities come la quantità di caffè che desideriamo:

#orderCoffee(@type, @coffeeCupSizes)
|
1 |
vorrei un cappuccino in una tazza media |
E adesso?
Il processo di annotazione richiede uno sforzo che coinvolge molte persone, fasi e strumenti. Per verificare la qualità delle annotazioni, per costruire un modello e per testarlo abbiamo bisogno di un processo iterativo come MATTER, proposto nel 2013 dai ricercatori Pustejovsky e Stubbs.
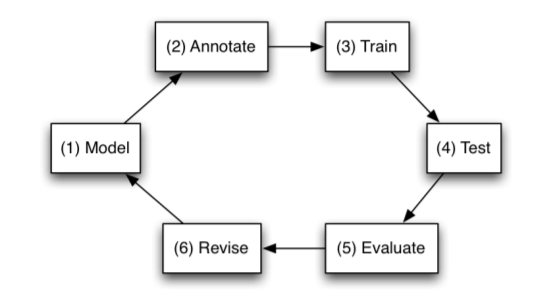 Se volessimo continuare ad annotare il dominio del caffé dovremmo dover cogliere le sfumature regionali di ordinare il caffè, magari consultando anche un esperto di dominio.
Se volessimo continuare ad annotare il dominio del caffé dovremmo dover cogliere le sfumature regionali di ordinare il caffè, magari consultando anche un esperto di dominio.

Bibliografia
[1] James Pustejovsky, Natural Language Annotation for Machine Learning, O’Really, 2012
Sitografia
[1] Come ordinare il caffè in un Bar italiano
[2] 34 modi diversi, tutti italiani, di prendere un caffè al bar
[3] 50 sfumature di caffè
[4] 29 modi (tutti italiani) di ordinare il caffè al bar