Le espressioni regolari (regex) si possono fare risalire alle prime ricerche del neurofisologo Warren McCulloch (1898-1969) e del giovane logico Walter Pitts (1923-1969) che nell’opera “A Logical Calculus of Ideas Immanent in Nervous Activity” (1943) furono i precursori dello studio delle reti neurali artificiali. Infine vennero sistematizzate nel 1956 dal matematico americano Stephene Cole Kleene (1909-1994) usando la nozione di “regular sets” nel dominio degli automi e dei linguggi formali.
Le regex vennero supportate nel 1966 dal computer scientist Ken Thompson, autore del linguaggio di programmazione b precursore del più famoso c di Dennis Ritchie (1941-2011) , nell’editor QED per Unix rendendole d’uso comune.
Python: import re
Python , attraverso il modulo re, offre due diversi metodi per lavorare con le Regex: il metodo match() per una corrispondenza ad inizio della stringa (string) e search() che controlla se c’è una corrispondenza in qualsiasi punto della stringa.
Capita a volte di dover cercare proprio il punto, oppure i caratteri [ o ]. Poiché fanno parte della sintassi regex in questi casi è necessario riccorrere all’escaping, ovvero precederli col carattere \ che rappresenta l’escape. Per evitare il doppio escape \\ dobbiamo mettere davanti alla stringa una r che sta ad indicare raw data.
Le regex sono valide in ogni linguaggio di programmazione: Java, JavaScript, Ruby, .Net, Python… risultando così un investimento di tempo sempre valido.
Utilizzi più comuni delle regex possono essere:
[1] Web scraping
[2] Data wrangling
[3] Parsing

search() Vs match()
|
1 2 3 |
import re string = (“abcde”) pattern = (r“c”) |
Il metodo match() controlla unicamente se ci sono match a inizio stringa:
|
1 2 3 |
match = re.match(pattern,string) print(match) none |
In questo esempio infatti non trova nessun match (none).
Il comportamento di match sembra essere più indicato per il controllo dei dati inseriti in un form data (input validation) come nome, cognome, email o telefono. Form che dovrà sempre seguire delle best practices per aumentarne l’efficienza (“Keep calm user interface best practices”, 2016).
Search() invece cerca i match anche all’interno della stringa restituendo un oggetto match con il relativo span.
|
1 2 3 4 5 |
string = (r“abcde”) pattern = (r“c”) match = re.search(pattern,string) print(match) <_sre.SRE_Match object; span=(2, 3), match=‘c’> |
Restituisce però solo il primo match che trova infatti ci restituisce solo c in posizione ‘(2,3)’, ma non quella in ‘(4,5)’. Questo comportamento é verificabile controllando lo span.
Per visualizzare il match semplicemente scriviamo:
|
1 2 |
print(match.group()) c |
findall()
Se volessimo trovare tutte le occorenze di una parola in una fraseil metodo findall() trova tutti i match in una frase, non solo la prima corrispondenza come search(). A differenza di search() che restituisce un oggetto match, findall restituisce una lista delle corrispondenze.
|
1 2 3 4 5 |
string = (“abcdce”) pattern = (r“c”) match = re.findall(pattern,string) print(match) [‘c’, ‘c’] |
Findall() cerca anche all’interno della stringa restituendo per esempio la ‘c’come avrebbe fatto anche search().
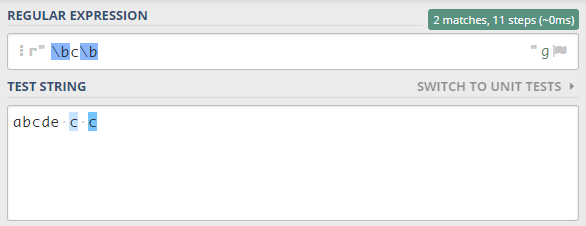
Il modulo findall() è l’ideale quando si desidera eseguire un’iterazione su più righe di un file, ma per trovare “whole words only” conviene utilizzare l’anchor \b (word bounderies).
Regex: online tool
Per un controllo più immediato delle espressioni regolari un ottimo tool online è regex101
settando l’opzione r (raw-data) e settando le regex flags con solo il modificatore di ricerca ‘g’ global (don’t return after the first match). Con queste impostazioni dovremmo avere lo stesso comportamento del metodo findall()
 Se usiamo il modificatore ‘m’ multiline, le ancore ^ e $ troveranno corrispondenza all’inizio e alla fine della riga invece che all’inizio e alla fine del documento intero, che si avrebbe nel caso in cui non utilizzassimo il modificatore.
Se usiamo il modificatore ‘m’ multiline, le ancore ^ e $ troveranno corrispondenza all’inizio e alla fine della riga invece che all’inizio e alla fine del documento intero, che si avrebbe nel caso in cui non utilizzassimo il modificatore.
Quando chiamiamo il metodo findall() su un oggetto regex, il secondo parametro non è l’argomento flags (perché è già stato usato durante la compilazione della regex) ma l’argomento pos, che dice al regex engine in quale punto della stringa iniziare la corrispondenza. Non prendendo quindi come argomento re.MULTILINE.
Credit image: xkcd
Sitografia
Documentazione
[1] A.M. Kuchling, Regular Expression HOWTO, Python 2.7.15