LLM-as-a-Judge: Sembra corretto, ma lo è davvero?
Risposte sbagliate, incomplete o inventate: con LLM-as-a-Judge puoi rilevare questi errori e tenere la qualità sotto controllo.


Hai mai chiesto qualcosa a un sistema AI e ricevuto una risposta che sembrava perfetta — fluente, sicura, ben strutturata — ma era sbagliata? O peggio, era quasi giusta? Il vero guaio è che, senza gli strumenti giusti, non lo scopri finché qualcuno non se ne accorge in produzione. A quel punto il danno è già fatto.
Come abbiamo visto nell'articolo precedente, la risposta a questo problema è — paradossalmente — usare un altro LLM. L'approccio si chiama LLM-as-a-Judge (LaaJ), e consiste nell'usare un modello per valutare l'output di un altro, in modo automatico e scalabile.
Un mese fa era giusta. Lo è ancora?🤔

Immagina di gestire un sistema di Q&A aziendale. A un certo punto aggiorni il prompt, fai qualche test, tutto sembra funzionare — e mandi in produzione. Ma qualcosa è cambiato in modo sottile: dove prima il modello rispondeva "entro 30 giorni", adesso dice "in circa un mese". Stesso significato, parole diverse. È un problema? È un miglioramento? È indifferente? Moltiplicato per centinaia di domande, capire se il sistema si è degradato o no diventa impossibile a mano.
Qui entra in gioco la valutazione basata su golden reference: ogni domanda ha una risposta di riferimento considerata corretta, e il sistema viene valutato misurando quanto le nuove risposte si discostano da quelle approvate. È essenzialmente un test di regressione — non per il codice, ma per il linguaggio.
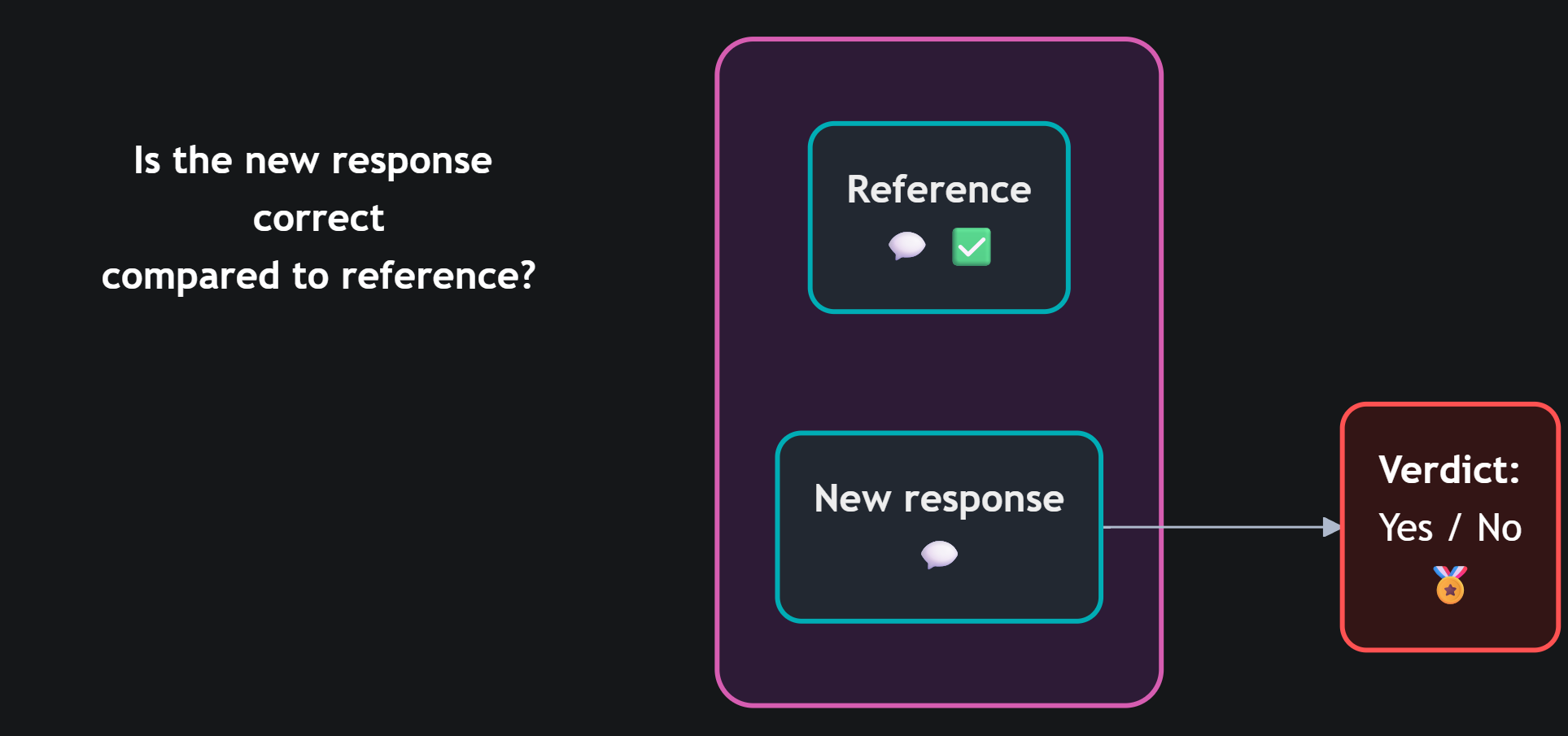
Il problema delle metriche classiche come ROUGE o BLEU è che confrontano le parole, non il significato. "Trenta giorni" e "un mese" hanno zero parole in comune, ma vogliono dire la stessa cosa — e BLEU le tratterebbe come risposte completamente diverse.
Il correctness judge risolve esattamente questo. È un LLM istruito a ragionare sulla coerenza semantica tra due risposte: non cerca sovrapposizioni lessicali, ma valuta se il contenuto informativo è equivalente, parzialmente diverso, o contraddittorio. Può essere affiancato da misure di similarità basate su embedding, ma il suo punto di forza è la capacità di ragionare — esattamente come farebbe un revisore umano, ma in modo scalabile.
La risposta c'è. Ma non è tutta la risposta🤯

A volte il problema non è che il modello risponda male — è che risponde a metà. Un utente chiede "Quali sono i vantaggi e gli svantaggi del lavoro da remoto?" e il modello risponde "Il lavoro da remoto offre maggiore flessibilità e riduce i tempi di spostamento." Tutto corretto. Ma gli svantaggi? Spariti.
La risposta è pertinente, fluente, convincente. E incompleta.
Il guaio è che questo tipo di lacuna è difficile da rilevare — soprattutto quando non hai una risposta di riferimento con cui confrontarti. Non puoi usare un correctness judge se non hai un golden da cui partire. Devi valutare la qualità guardando solo la domanda e la risposta.
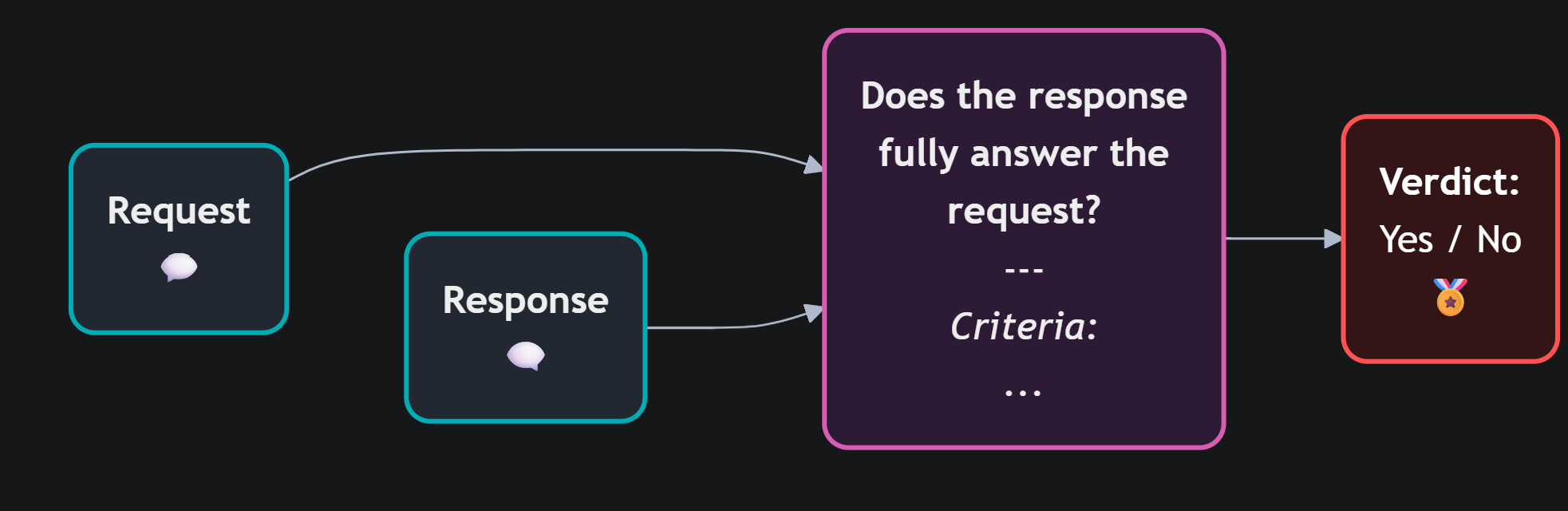
Per farlo, dobbiamo ragionare su due dimensioni distinte. La prima è la rilevanza (relevance): la risposta è effettivamente attinente a quanto chiesto? La seconda è la completezza (completeness): la risposta affronta tutti gli elementi della domanda, o ne ignora qualcuno?
Nel nostro esempio, la rilevanza è alta — il modello parla davvero di lavoro da remoto — ma la completezza è insufficiente: ha risposto solo alla metà comoda della domanda. Queste valutazioni si prestano sia a test offline che al monitoraggio continuo in produzione.
Molti framework moderni e diversi studi sulla valutazione evidenziano come, in assenza di risposte di riferimento, gli stessi LLM possano fungere da valutatori zero-shot o con poche istruzioni (few-shot), stimando queste dimensioni di qualità in modo automatico.
Hai la risposta. Sei sicuro di aver cercato nel posto giusto? 😭

Immagina un chatbot aziendale a cui un dipendente chiede: "Posso portare il cane in ufficio?" Il sistema recupera tre documenti: uno sul regolamento animali in sede, uno sulla policy di smart working e uno sul codice di abbigliamento. Il modello genera una risposta che sembra sensata — ma si è basato su tutti e tre i documenti, di cui solo uno era davvero utile.
Il risultato può essere confuso, incompleto, o fuorviante. E il problema non è il modello — è quello che gli è stato messo davanti.
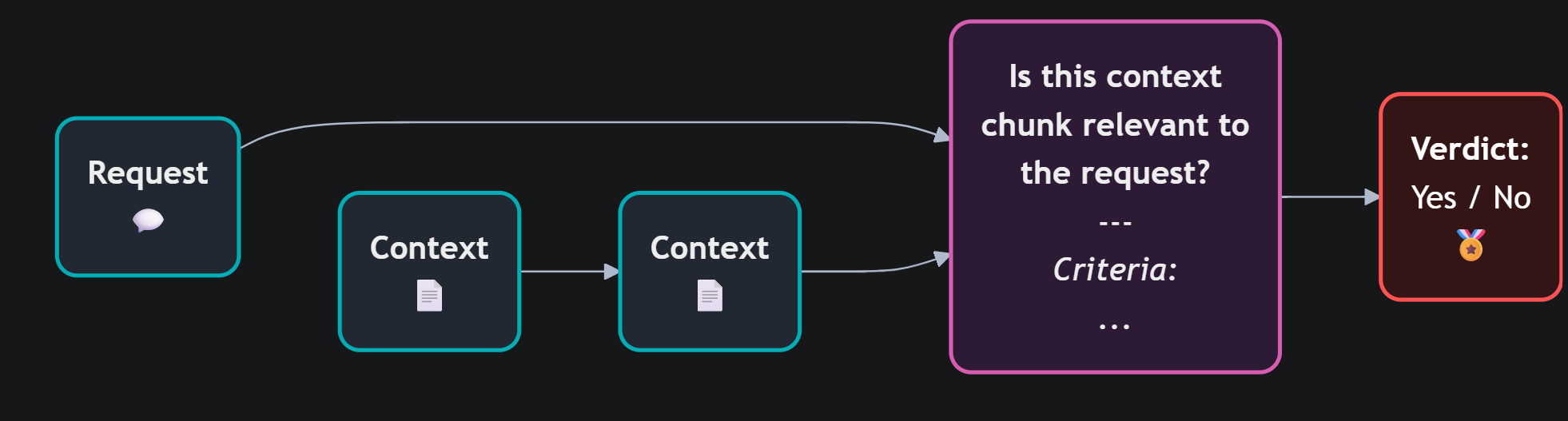
Nei sistemi RAG la qualità si valuta in due fasi distinte, e tenerle separate è fondamentale. La prima è la fase di retrieval: i documenti recuperati sono davvero pertinenti alla domanda? La seconda è la fase di generazione: dato quel contesto, la risposta prodotta è accurata e completa?
Per misurare la qualità del retrieval esistono metriche standard mutuate dall'information retrieval classico — Precision@K, NDCG e MRR — che valutano quanto efficacemente il sistema posiziona i documenti rilevanti in cima alla lista. Nel nostro esempio, un retriever che funziona bene avrebbe portato il regolamento animali al primo posto, ignorando o penalizzando gli altri due.
Per applicare queste metriche serve però sapere quali documenti sono rilevanti per ogni query — le cosiddette relevance labels. Possono essere assegnate manualmente, ma sempre più spesso vengono generate da un context relevance judge: un LLM istruito a valutare la pertinenza di ogni documento rispetto alla query, in modo automatico e scalabile — un approccio che sta diventando lo standard nella letteratura recente.
La risposta è corretta. La parte inventata un po' meno🤔

Un dipendente chiede: "Quanti giorni di ferie ho diritto a prendere consecutivamente?" Il sistema recupera il documento giusto: "Ogni dipendente ha diritto a un massimo di 15 giorni consecutivi di ferie, previa approvazione del responsabile." Il modello risponde: "Puoi prendere fino a 15 giorni consecutivi di ferie. Inoltre, per periodi superiori a 10 giorni, è previsto un bonus di produttività al rientro."
Il dipendente, ovviamente, va subito a controllare la busta paga. Il bonus non c'è. Non c'è mai stato. Non compariva nel documento recuperato, non esiste nella policy aziendale — il modello se l'è inventato con la stessa sicurezza con cui aveva riportato i 15 giorni corretti.
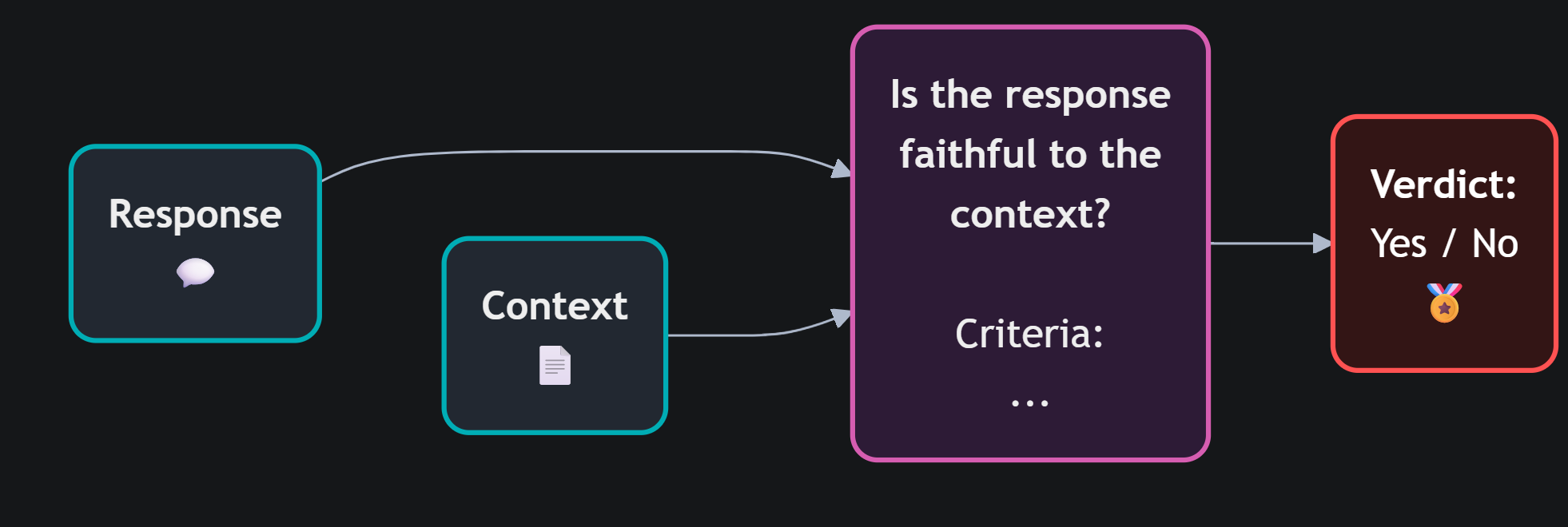
Questo è il problema delle allucinazioni nei sistemi RAG: il modello riceve documenti esterni, li usa correttamente — e poi aggiunge qualcosa di suo. La risposta è fluente, convincente, plausibile. E in parte falsa.
Per rilevare questo tipo di errore si usa un faithfulness judge: un LLM istruito a verificare se ogni affermazione nella risposta è supportata dal contesto recuperato. Non valuta se la risposta è vera in assoluto, ma se è fedele alle fonti — se il modello si è attenuto a quello che aveva letto o ha deciso di arricchire la risposta di proprio pugno.
🔗 Sitografia
[0] Cameron R. Wolfe, Chain of Thought Prompting for LLMs, 24/04/2023
[1] James Zhu et Al, LLM-as-Judge: Evaluating and Improving Language Model Performance in Production, Twilio, 01/05/2025
[2] Cameron R. Wolfe, Using LLMs for Evaluation, Blog, 22/07/2024
[3] Cameron R. Wolfe, Finetuning LLM Judges for Evaluation, Blog, 02/12/2024
[4] Dave Davies, LLM evaluation: Metrics, frameworks, and best practices, Weights & Biases, 12/02/2025
[5] Dave Davies, LLM evaluation metrics: A comprehensive guide for large language models, Weights & Biases, 03/05/2025
[6] Vision X, LLM-as-a-Judge: The Future of Evaluating AI Models with Accuracy and Scale, Vision X, 09/05/2025
[7] Notre Dame–IBM Tech Ethics Lab, Can we trust AI to judge? Two research teams explore the opportunities and limitations of LLM-as-a-Judge, Blog Post, 24/07/2025
[8] Arize, Evidence-Based Prompting Strategies for LLM-as-a-Judge: Explanations and Chain-of-Thought, Blog, 20/08/2025
[9] Sebastian Raschka, Understanding the 4 Main Approaches to LLM Evaluation (From Scratch), Head of AI, 05/10/2025
[10] Jeffrey Ip, LLM-as-a-Judge Simply Explained: The Complete Guide to Run LLM Evals at Scale, Confident AI, 10/10/2025
[11] , LLM-as-a-judge: a complete guide to using LLMs for evaluations, Evidentlyai, 23/07/ 2025
[12] , LLM-As-Judge: 7 Best Practices & Evaluation Templates,
[13] , LLM-as-a-Judge: Rethinking How We Evaluate AI Systems, 25/12/2025
🔎 Papers
[0] Wang, Peiyi et al, Large language models are not fair evaluators, arXiv preprint arXiv:2305.17926, 2023
[1] Yang et al, G-EVAL: NLG Evaluation using GPT-4 with Better Human Alignment, arXiv:2303.16634, 2023
[2] Zheng et al, Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena, arxiv:2306.05685, NeurIPS, 2023. Il paper fondamentale su LaaJ. Dimostra che GPT-4 raggiunge oltre l'80% di accordo con le preferenze umane (lo stesso livello osservato tra due valutatori umani). Definisce LaaJ come "a scalable and explainable way to approximate human preferences." . Introduce pairwise comparison e single-answer grading come protocolli di valutazione.
[3] , RevisEval: Improving LLM-as-a-Judge via Response-Adapted References, arXiv:2410.05193, 2024
[4] Gu et al, A Survey on LLM-as-a-Judge, arxiv:2411.15594, 2o24. Survey completo che copre scalabilità, costo-efficacia, consistenza e strategie per migliorare l'affidabilità dei giudici LLM.
[5] Ye et al, Justice or Prejudice? Quantifying Biases in LLM-as-a-Judge, arxiv:2410.02736 , 2o24. Quantifica i bias dei giudici LLM (posizione, verbosità, self-enhancement).
[6] , Judging the Judges: A Systematic Study of Position Bias in LLM-as-a-Judge,
[7] Li et al, From Generation to Judgment: Opportunities and Challenges of LLM-as-a-judge, arxiv:2411.16594 , 2025. Survey che documenta come le metriche tradizionali (matching-based) falliscano in scenari open-ended e dinamici, e come gli LLM offrano valutazioni multi-dimensionali.
📺Videografia
[0] Afshine Amidi, Stanford CME295 Transformers & LLMs | Autumn 2025 | Lecture 8 - LLM Evaluation, Youtube, 21/11/2025