LLM-as-a-Judge: Oltre il rumore
Dove c'è giudizio c'è rumore. Scopri come LLM-as-a-Judge trasforma la valutazione AI in un processo strutturato, riproducibile e scalabile.


Hai mai passato settimane a costruire un sistema AI, solo per scoprire di non avere la minima idea se stia effettivamente funzionando? 🤔 Il primo istinto è misurare tutto introducendo nuove metriche — e il sistema diventa rapidamente ingestibile.
Questa sensazione non è un'anomalia del progetto. Man mano che le capacità degli LLM sono progredite negli ultimi anni, le metriche legacy come BLEU e ROUGE — storicamente utilizzate per misurare overlap tra testi — sono diventate sempre meno efficaci. Lo stesso vale per la semantic similarity, tradizionalmente calcolata tramite embeddings o modelli basati su BERT. Sono state progettate per un'epoca in cui gli LLM erano strumenti molto più semplici — e oggi mostrano tutti i loro limiti.
La distanza tra quello che queste metriche misurano e quello che ci interessa davvero sapere è diventata enorme: la risposta è corretta? È completa? È affidabile? È fedele alle fonti?
Che cos'è LLM as a judge?🤔
LLM-as-a-Judge (LaaJ) è un metodo di valutazione in cui un LLM viene usato come giudice per valutare, confrontare o classificare gli output di altri sistemi generativi secondo criteri espliciti. Con la crescente versatilità degli LLM, gli strumenti valutativi tradizionali hanno smesso di essere utili.

Conventional reference-based metrics, such as BLEU and ROUGE, have been shown to have relatively low correlation with human judgments, especially for tasks that require creativity and diversity.
– G-Eval, Liu et al.
Dietro BLEU e ROUGE c'è un'idea semplice come contare le parole in comune. Sono metriche progettate per compiti ristretti con risposte di riferimento definite, rendendole inadatte a valutare output open-ended, dove servono giudizi su coerenza, utilità e qualità semantica. Inoltre correlano male con le preferenze umane: una risposta può ottenere un punteggio alto pur risultando poco utile o incoerente per un utente reale. Questo è particolarmente critico perché i moderni LLM vengono allineati tramite feedback umano (RLHF) proprio su queste qualità.
La diffusione di LaaJ è stata accelerata da iniziative come MT-Bench e Chatbot Arena (Zheng et al., 2023). Il primo è un benchmark di 80 domande multi-turno in cui un LLM giudice valuta le risposte dei modelli su otto categorie (ragionamento, scrittura, coding, ecc.); il secondo è una piattaforma crowdsourced dove gli utenti confrontano le risposte di due modelli anonimi, generando una classifica Elo da centinaia di migliaia di voti reali. Insieme, hanno mostrato che giudici LLM forti raggiungono un accordo con le preferenze umane superiore all'80 %, paragonabile a quello tra annotatori umani.
Il rumore del giudizio 🎯
Dove c’è giudizio, c’è rumore, e più di quanto non si pensi
- Noise, Daniel Kahneman
La valutazione umana, spesso usata come ground truth, rimane un collo di bottiglia costoso, lento e imperfetto per sua natura. Nel suo libro "Noise: A Flaw in Human Judgment", lo psicologo Daniel Kahneman (1934-2024) definisce il giudizio come "una misurazione il cui strumento è la mente umana". Come ogni strumento di misura imperfetto o mal calibrato, la mente è soggetta non solo a bias — errori sistematici e prevedibili — ma anche a rumore, ovvero a una variabilità indesiderata nei giudizi.

Kahneman dimostra che valutatori diversi — o persino lo stesso valutatore in momenti differenti (occasional noise) — possono produrre giudizi significativamente divergenti di fronte agli stessi input. Per chiarire questa instabilità, ricorre alla metafora del tiro al bersaglio 🎯.
Quando i colpi sono dispersi attorno al centro senza una direzione costante, l'errore non è sistematico ma casuale: è rumore. Non si tratta di incompetenza, bensì del fatto che il processo di valutazione è intrinsecamente instabile e sensibile a fattori esterni come l'umore, la stanchezza o il contesto, che influenzano inconsapevolmente il giudizio. Quando invece i colpi risultano raggruppati ma costantemente spostati rispetto al centro, l'errore è bias.
Un valutatore che sottovaluta sistematicamente tutte le risposte di un modello colpisce sempre fuori centro, ma nella stessa direzione. Un valutatore che sottovaluta le risposte di lunedì e le sovrastima di martedì spara colpi dispersi senza schema — come i sommelier esperti che, secondo Kahneman, raramente concordano con sé stessi quando valutano lo stesso vino in momenti diversi.

Nella pratica convivono entrambi: lo stesso valutatore può presentare bias e rumore insieme. La variabilità emerge sia tra valutatori diversi sia all'interno dello stesso valutatore in occasioni differenti.
Teoria operativa del giudizio
LLM-as-a-Judge non è soltanto una tecnica di valutazione, ma una teoria operativa del giudizio. Sposta il problema dall’assegnazione di un punteggio alla costruzione esplicita dei criteri, rendendo visibile ciò che nelle valutazioni umane resta spesso implicito, instabile o rumoroso. In questo senso, il giudizio dell’LLM non elimina il noise descritto da Kahneman, ma lo rende osservabile, controllabile e — entro certi limiti — riproducibile.
L'approccio è stato esplorato inizialmente dopo il rilascio di GPT-4, il primo LLM in grado di valutare la qualità dell'output di altri modelli. Da allora, diverse pubblicazioni hanno analizzato LaaJ, individuando best practices per la sua implementazione e bias importanti di cui tenere conto.
Studi recenti mostrano che, in diversi contesti, i giudizi prodotti da LLM ben istruiti raggiungono un livello di accordo con valutatori umani comparabile a quello tra due valutatori umani indipendenti. In altre parole, l'LLM non è perfetto, ma spesso non è meno coerente dell'essere umano medio, soprattutto quando il task è linguistico, comparativo o qualitativo.
Tuttavia, la vera sfida non è usare un LLM come giudice, ma capire quando fidarsi del suo giudizio. La ricerca attuale si concentra su aspetti critici come i bias dell'LLM, la coerenza delle valutazioni nel tempo e la robustezza rispetto a input variabili.
Come funziona LaaJ? 🤔
L'approccio LLM-as-a-Judge funziona perché sfrutta un principio semplice: per un LLM, così come per un essere umano, è più facile valutare un testo che generarlo da zero (Song et al., 2024). In termini di scalabilità, un giudice AI può processare migliaia di output in pochi secondi a una frazione del costo della revisione umana, comprendendo contesto, tono e semantica — aspetti su cui le metriche legacy falliscono in scenari open-ended (Li et al., 2024). Può valutare simultaneamente più dimensioni qualitative in parallelo — correctness, clarity, relevance, aderenza alle linee guida — qualcosa di difficile da ottenere in modo consistente con valutatori umani su grandi dataset (Gu et al., 2024).

Un altro vantaggio chiave è l'explainability: a differenza delle metriche tradizionali, che restituiscono un semplice numero, un giudice LLM genera spiegazioni strutturate per i punteggi che assegna, rendendo ogni valutazione interpretabile e azionabile.
Pensiamo a quanto spesso ci capita di ricorrere a scale non calibrate — come il classico 1-5 — applicate a molteplici dimensioni. Cosa differenzia realmente un 3 da un 4? La linea di demarcazione è sfumata e soggettiva: diversi valutatori potrebbero interpretare queste scale in modo diverso, generando incoerenza nei dati.
Un giudice LLM, invece, accompagna ogni punteggio con una motivazione esplicita, riducendo questa ambiguità. Zheng et al. (2023) definiscono LaaJ come "a scalable and explainable way to approximate human preferences", dimostrando che GPT-4 raggiunge oltre l'80% di accordo con le preferenze umane — lo stesso livello osservato tra due valutatori umani indipendenti.
Types of LLM judges
Per eseguire valutazioni con LLM-as-a-Judge, tutto ciò che serve è un prompt. Esistono però diverse strutture comunemente utilizzate, che si differenziano per come il giudice formula il proprio giudizio (Li et al., 2024; Zheng et al., 2023):
- Pairwise comparison (A vs B): al giudice vengono presentati una domanda e due risposte generate da modelli diversi, e gli viene chiesto di identificare la migliore.
- Pointwise evaluation: al giudice viene fornita una singola risposta e gli viene chiesto di assegnare un punteggio, ad esempio su una scala da 1 a 5 o con una valutazione binaria (Pass/Fail).
- Reference-guided scoring: al giudice viene fornita una soluzione di riferimento, oltre alla domanda e alla risposta, per ancorare il processo di valutazione a un ground truth.
Trasversalmente a queste strutture, i giudici si distinguono anche per il tipo di input che ricevono: possono essere reference-based (con una risposta corretta di riferimento) o reference-free (senza riferimento, basandosi solo sulla qualità intrinseca della risposta) (Gu et al., 2024). Il reference-guided scoring è, in questo senso, un caso specifico di valutazione reference-based.
Ciascuna di queste tecniche può essere combinata con il chain-of-thought prompting (CoT) per migliorare la qualità della valutazione. In pratica, è sufficiente aggiungere al prompt del giudice un'istruzione come "fornisci una spiegazione passo-passo del tuo punteggio".
È tuttavia fondamentale che l'LLM produca la motivazione prima del punteggio, e non dopo (Wang et al., 2023). Se il modello emette prima il punteggio e poi la spiegazione, tende a costruire una giustificazione a posteriori che non riflette il reale processo decisionale.
Chiedendo invece la motivazione prima del punteggio, si ottiene una valutazione più coerente e affidabile. Quale strategia utilizzare? Non esiste un approccio migliore in assoluto: la scelta dipende dalla disponibilità di una golden answer, dalla natura del task (soggettivo o fattuale) e dalla fase del progetto (esplorazione o produzione).
Rulebook
Il rulebook (o rubrica) è un documento strutturato che formalizza i criteri di valutazione — abilitando metodologie come il direct scoring — e fornisce al giudice istruzioni precise su come formulare il giudizio. Il risultato è una valutazione sistematica e riproducibile, non più affidata all'interpretazione del momento. All’LLM può essere richiesto di valutare dimensioni specifiche della risposta, come la correctness — ossia la veridicità e la coerenza logica dei contenuti —, la clarity, intesa come comprensibilità e chiarezza espositiva, la safety, che riguarda la conformità e l’assenza di contenuti potenzialmente dannosi, la reasoning depth, cioè il livello di profondità del ragionamento e dell’analisi, e infine la relevance, che misura quanto la risposta sia realmente pertinente alla domanda e agli obiettivi del task.
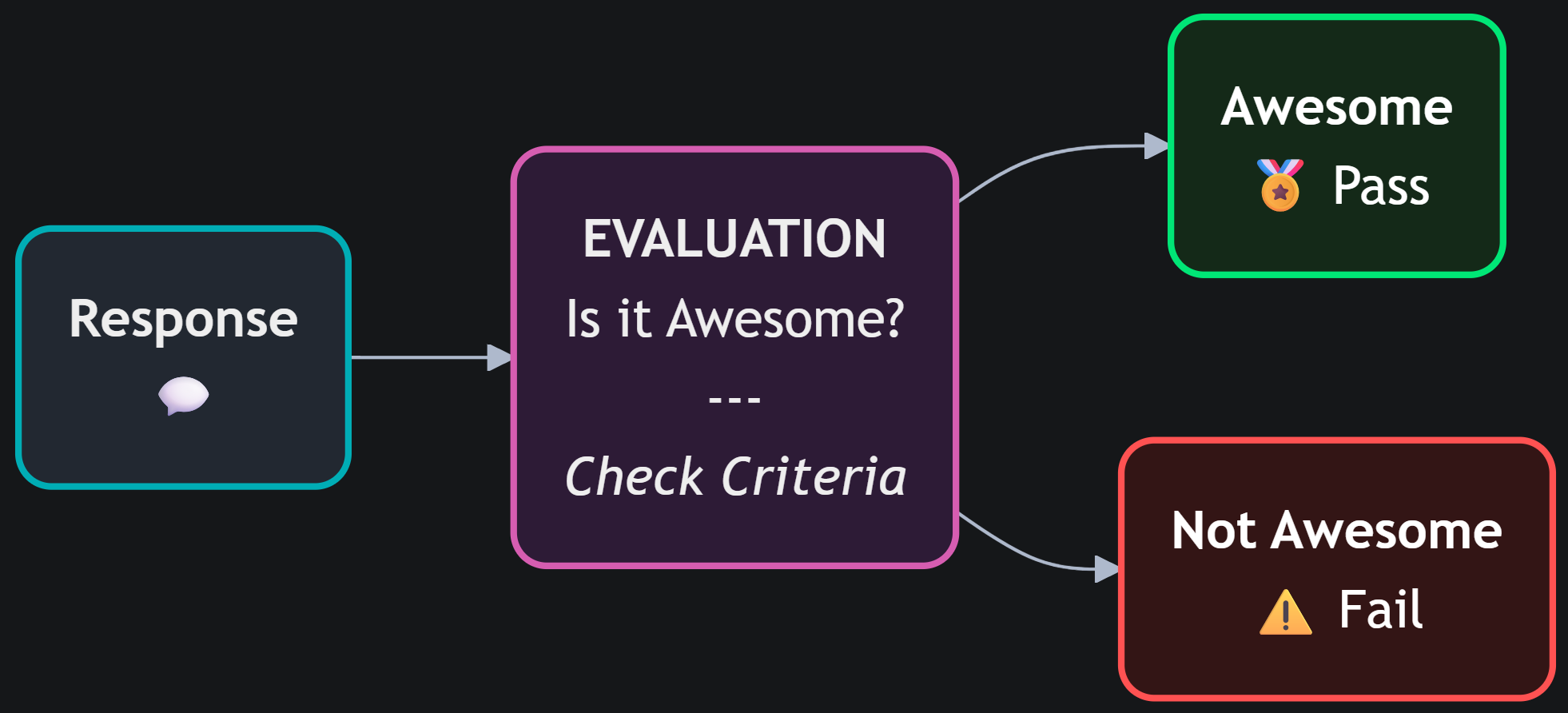
Per ottenere risultati affidabili, due principi fanno la differenza. Il primo è preferire metriche binarie: iniziare con valutazioni semplici come "Pass/Fail" o "Sì/No" è spesso più efficace e meno rumoroso rispetto a scale numeriche complesse come 1-10. Il secondo è definire criteri specifici: evitare metriche generiche come "qualità" e preferire domande concrete — "La risposta contiene allucinazioni?" o "Il tono è professionale?"
Ma cosa succederebbe se cambiassi la rubrica?🤔
Modificare criteri, definizioni o priorità significa ridefinire il modo in cui il giudice interpreta la qualità — possono variare punteggi, emergere nuovi bias, e risposte prima considerate migliori potrebbero non esserlo più. In pratica, non stai solo aggiornando le regole di valutazione: stai ridefinendo implicitamente il task stesso, rendendo più difficile confrontare risultati ottenuti con rubriche diverse.
Valutazione basata su reference
Quando si dispone di una golden answer o di un ground truth, si utilizza la valutazione basata su reference. In questo caso, l'LLM Judge confronta la risposta generata dal sistema con la risposta ideale, verificando correttezza, completezza e fedeltà. A seconda del tipo di informazione disponibile, la valutazione reference-based può assumere diverse forme:
- Answer + Reference Answer: la forma più diretta, utile quando si dispone di una risposta corretta con cui confrontare l'output. Zhang et al. (RevisEval, 2024) mostrano che fornire un riferimento adattato alla risposta migliora significativamente l'affidabilità del giudizio rispetto alla valutazione reference-free.
- Answer + Retrieved Context: utilizzato nei sistemi RAG, dove il contesto recuperato funge da riferimento per verificare fedeltà e correttezza della risposta. In alcuni setup si includono anche tutti e tre gli elementi — domanda, risposta e contesto — per una valutazione più completa.
In tutti questi casi, invece di passare un singolo input al prompt di valutazione, si includono due o più testi e si spiega al giudice come questi si relazionano tra loro. Esiste anche una forma opposta, la valutazione reference-free, in cui il giudice non dispone di alcuna risposta di riferimento e valuta la qualità dell'output basandosi unicamente sulla domanda e su criteri generali come fluidità, coerenza e utilità. Questo è il setup tipico dei sistemi chatbot e Q&A — utilizzato tra gli altri da Zheng et al. (2023) con MT-Bench — ed è più adatto per compiti creativi o per quelli che ammettono più risposte corrette.
La scelta tra i due approcci dipende da ciò che è disponibile nella propria pipeline e dall'aspetto della qualità che si vuole misurare.
La scelta delle metriche non è arbitraria. Ogni dimensione ha senso solo se il giudice dispone degli input necessari per valutarla. La faithfulness — quanto la risposta è fedele alle informazioni contenute nel contesto recuperato — non può essere misurata senza quel contesto. La factual accuracy — quanto i fatti affermati nella risposta sono corretti rispetto a una risposta ideale — non può essere valutata senza un riferimento. Chiedere al giudice di misurare qualcosa che non può vedere non produce informazione, produce rumore.
Anatomia di un Giudice
Costruire un LLM judge affidabile richiede attenzione su due fronti distinti: la qualità del giudizio e la sua stabilità operativa.
Qualità del giudizio
La prima accortezza è evitare che il modello valuti testi prodotti da sé stesso o da modelli troppo affini. Gli LLM tendono a favorire le proprie risposte quando assumono il ruolo di giudici — un effetto noto come self-preference bias — che può estendersi anche a modelli della stessa famiglia.
Per ridurre questo rischio, è preferibile separare chiaramente generatore e giudice: ad esempio, usare un modello della famiglia GPT per la generazione e un modello di un'altra famiglia per la valutazione, come Claude, Gemini o LLaMA.
Un secondo elemento cruciale riguarda il modo in cui il giudice viene indotto a ragionare. Chiedergli di esplicitare prima una motivazione (rationale) e solo successivamente di emettere il verdetto migliora sensibilmente la qualità del giudizio, rendendolo più stabile e meno soggetto a distorsioni. Questo principio — già discusso nella sezione sui tipi di giudici — vale anche qui come linea guida operativa generale.
Stabilità e consistenza operativa
Dal punto di vista operativo, è best practice forzare l'output del giudice in una struttura formale come il formato JSON, così da separare chiaramente decisione e spiegazione e facilitare l'analisi automatica dei risultati. Impostare la temperatura a zero riduce la variabilità stocastica e aumenta la consistenza delle valutazioni nel tempo — particolarmente importante quando si vuole confrontare i risultati di sessioni diverse. Infine, è essenziale mantenere il prompt snello e focalizzato.
Prompt troppo lunghi o sovraccarichi di informazioni tendono a favorire risposte più prolisse indipendentemente dalla loro qualità reale, introducendo un bias che penalizza le risposte concise.
Chi giudica il giudice? 🤔
Creare un giudice LLM è un processo di calibrazione continua che include la meta-valutazione, ovvero valutare il valutatore stesso. Il punto di partenza è sempre lo stesso. Capire se il giudice vede la qualità nello stesso modo in cui la vedono gli esperti del tuo dominio. Tutto il resto — il prompt, gli esempi, le metriche — serve a colmare la distanza tra i due.
- Crea un Golden Dataset: raccogli un insieme di input e output reali e falli annotare da esperti umani (Human Ground Truth). Bastano anche 50-100 esempi per iniziare, avendo cura di includere casi limite e categorie rappresentative del tuo sistema.
- Scrivi il Prompt del Giudice: definisci chiaramente i criteri di valutazione nel prompt, seguendo le indicazioni del Rulebook.
- Esegui e Confronta: fai girare il giudice sul dataset e confronta i suoi voti con quelli umani.
- Calcola l'allineamento: misura quanto spesso l'LLM è d'accordo con l'umano tramite il tasso di accordo. Per una misura più robusta, puoi ricorrere a metriche come Cohen's Kappa, che tiene conto dell'accordo attribuibile al caso e non alla coincidenza.
- Itera: se l'accordo è basso, migliora il prompt del giudice, fornisci esempi (Few-Shot) o arricchisci il dataset con ulteriori casi limite, finché il giudice non si allinea con il giudizio umano.
LLM evaluation prompts
Un prompt di valutazione non è diverso da qualsiasi altro prompt — ma gli errori di progettazione qui hanno un costo più alto, perché si propagano su tutte le valutazioni. Strutturarlo bene sin dall'inizio riduce il rumore e rende i risultati comparabili nel tempo.
Un buon prompt di valutazione dovrebbe sempre includere un ruolo ("Sei un giudice imparziale..."), che ancori il comportamento del modello; un task chiaro ("Valuta l'accuratezza della seguente risposta..."); gli input necessari — la domanda dell'utente, la risposta del modello e, se disponibili, il contesto o la risposta di riferimento; una definizione dei criteri che spieghi in dettaglio cosa costituisce un giudizio positivo o negativo; e infine un formato di output esplicito, preferibilmente JSON, che separi punteggio e motivazione e faciliti l'analisi automatica.
score e rationaleUn esempio semplificato: "Valuta questa risposta del servizio clienti su accuratezza, tono e utilità. Fornisci una critica dettagliata e poi un voto binario (Pass/Fail). Rispondi in formato JSON."
LLM observability in production
Portare LaaJ in produzione significa spostarlo da strumento di valutazione offline a componente attivo del sistema. Non si tratta più di valutare campioni in batch dopo il fatto, ma di osservare la qualità in tempo reale, su scala, in modo continuo.
Vale la pena partire da una distinzione spesso sottovalutata. La valutazione in produzione si divide in due fasi temporalmente separate.
La fase di offline eval (pre-deployment), eseguita prima del rilascio, opera su dataset curati e permette di validare cambiamenti al sistema prima che raggiungano gli utenti. La fase di online eval (post-deployment), attiva dopo il deploy, lavora su traffico reale in modo asincrono — il giudice valuta le risposte dopo che queste sono già state consegnate all'utente, senza impattarne la latency percepita.
Questa separazione non è un dettaglio architetturale. È ciò che determina quando e perché si usano i pattern descritti di seguito.
Tre sono i pattern più comuni.
- Sampling: non è necessario valutare il 100% delle richieste. Si può campionare una percentuale rappresentativa (es. 10–20%) o attivare il giudice selettivamente sui casi sospetti, riducendo i costi senza perdere copertura significativa. Va ricordato che il costo di una singola valutazione con un modello forte varia tra $0.01 e $0.10: su decine di migliaia di richieste giornaliere, questa variabile diventa un constraint di design, non un dettaglio. Una strategia efficace è la tiered architecture: usare un modello più piccolo e veloce per la grande maggioranza delle valutazioni, riservando il modello più potente ai casi ambigui o ad alto rischio.
- Real-time guardrails: per use case critici — come la rilevazione di jailbreak o contenuti dannosi — il giudice può girare in parallelo alla generazione e bloccare output problematici prima che raggiungano l'utente. In contesti ad alto rischio, vale la pena considerare un panel di giudici invece di uno solo (approccio noto come LLM-as-a-Jury), dove il verdetto finale è determinato a maggioranza, riducendo la variabilità del singolo giudice.
- Root Cause Analysis: i log delle valutazioni negative sono la fonte più preziosa per capire dove il sistema fallisce. Separare i problemi di retrieval (il contesto recuperato era sbagliato?) da quelli di generation (il modello ha allucinato?) permette di intervenire nel punto giusto.
Strumenti come Langfuse — ottimale per gestire le evaluation queue, le trace e il sampling asincrono — e Arize Phoenix — più orientato al real-time monitoring e ai guardrails — rendono questi dati navigabili e azionabili. Usato in questo modo, LaaJ non è solo un metro di misura: è un sistema nervoso che rende il tuo modello osservabile.
LaaJ non è la risposta - è la domanda giusta 🤔
LLM-as-a-Judge non risolve il problema della valutazione: lo sposta su un piano più governabile. Non elimina il rumore di cui parla Kahneman — lo rende visibile, strutturato, iterabile. Ed è proprio questa la sua promessa più concreta.
Le metriche legacy misuravano ciò che era facile da misurare. LaaJ ci sfida a misurare ciò che conta davvero: la risposta è corretta? È utile? È affidabile? Formalizzare queste domande in una rubrica esplicita è già, di per sé, un atto epistemico — costringe il team a definire cosa significa "qualità" per il proprio sistema, prima ancora di delegare il giudizio a un modello. Questo non significa fidarsi ciecamente del giudice LLM. Significa trattarlo come si tratta qualsiasi strumento di misura: calibrarlo, validarlo, monitorarlo nel tempo.
Il golden dataset ⭐, il tasso di accordo con gli esperti umani, il ciclo iterativo di meta-valutazione non sono passi opzionali — sono la struttura che rende il giudizio riproducibile. In un panorama in cui i sistemi AI diventano sempre più complessi, avere un framework di valutazione robusto non è un dettaglio ingegneristico. È una precondizione per costruire qualcosa in cui avere fiducia.
📚Bibliografia
[0] Daniel Kahneman , Pensar rápido, pensar despacio, Penguin Random House, Prima edizione, 2012
[1] Daniel Kahneman , Ruido: Una falla en el juicio humano, Penguin Random House, Prima edizione, 2021
🔗 Sitografia
[0] Cameron R. Wolfe, Chain of Thought Prompting for LLMs, 24/04/2023
[1] Cameron R. Wolfe, A Practitioners Guide to Retrieval Augmented Generation (RAG), 05/02/2024
[2] Aparna Dhinakaran, Evan Jolley, Why You Should Not Use Numeric Evals for LLM As a Judge, Arize, 08/03/2024
[3] Cameron R. Wolfe, Using LLMs for Evaluation, Blog, 22/07/2024
[4] Cameron R. Wolfe, Finetuning LLM Judges for Evaluation, Blog, 02/12/2024
[5] Dave Davies, LLM evaluation: Metrics, frameworks, and best practices, Weights & Biases, 12/02/2025
[6] James Zhu et Al., LLM-as-Judge: Evaluating and Improving Language Model Performance in Production, Twilio, 01/05/2025
[7] Dave Davies, LLM evaluation metrics: A comprehensive guide for large language models, Weights & Biases, 03/05/2025
[8] Vision X, LLM-as-a-Judge: The Future of Evaluating AI Models with Accuracy and Scale, Vision X, 09/05/2025
[9] Notre Dame–IBM Tech Ethics Lab, Can we trust AI to judge? Two research teams explore the opportunities and limitations of LLM-as-a-Judge, Blog Post, 24/07/2025
[10] Redazione, Evidence-Based Prompting Strategies for LLM-as-a-Judge: Explanations and Chain-of-Thought, Arize, 20/08/2025
[11] Sebastian Sigl, The 5 Biases That Can Silently Kill Your LLM Evaluations (And How to Fix Them), Personal Blog, 19/09/2025
[12] Sebastian Raschka, Understanding the 4 Main Approaches to LLM Evaluation (From Scratch), Head of AI, 05/10/2025
[13] Redazione, LLM-as-a-judge: a complete guide to using LLMs for evaluations, Evidently AI, 23/07/ 2025
[14] Jeffrey Ip, LLM-as-a-Judge Simply Explained: The Complete Guide to Run LLM Evals at Scale, Confident AI, 10/10/2025
[15] Redazione, F.A.Q on LLM judges: 7 questions we often get, Evidently AI, 31/10/2025
[16] Doug Turnbull, LLM Judges aren’t the shortcut you think, Softwaredoug, 02/11/2025
[17] Juan C Olamendy, Using LLM-as-a-Judge to Evaluate Agent Outputs: A Comprehensive Tutorial, Medium, 05/11/2025
[18] Devaraj Durairaj, LLM as a Judge — A Practical, Human Guide for Engineers and Curious Minds, Medium, 26/11/2025
[19] Nagesh Singh Chauhan, LLM-as-a-Judge: Rethinking How We Evaluate AI Systems, 25/12/2025
[20] Marlies Mayerhofer, LLM-as-a-Judge Evaluation: Complete Guide, Langfuse, 12/02/2026
📺Videografia
[0] Afshine Amidi, Stanford CME295 Transformers & LLMs | Autumn 2025 | Lecture 8 - LLM Evaluation, Youtube, 21/11/2025
🔎 Papers
[0] Wang, Peiyi et al., Large language models are not fair evaluators, arXiv preprint arXiv:2305.17926, 2023
[1] Yang et al., G-EVAL: NLG Evaluation using GPT-4 with Better Human Alignment, arXiv:2303.16634, 2023
[2] Zheng et al., Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena, arxiv:2306.05685, NeurIPS, 2023. Il paper fondamentale su LaaJ. Dimostra che GPT-4 raggiunge oltre l'80% di accordo con le preferenze umane (lo stesso livello osservato tra due valutatori umani). Definisce LaaJ come "a scalable and explainable way to approximate human preferences." . Introduce pairwise comparison e single-answer grading come protocolli di valutazione.
[3] , RevisEval: Improving LLM-as-a-Judge via Response-Adapted References, arXiv:2410.05193, 2024
[4] Gu et al., A Survey on LLM-as-a-Judge, arxiv:2411.15594, 2o24. Survey completo che copre scalabilità, costo-efficacia, consistenza e strategie per migliorare l'affidabilità dei giudici LLM.
[5] Ye et al., Justice or Prejudice? Quantifying Biases in LLM-as-a-Judge, arxiv:2410.02736 , 2o24. Quantifica i bias dei giudici LLM (posizione, verbosità, self-enhancement).
[6] Li et al., Judging the Judges: A Systematic Study of Position Bias in LLM-as-a-Judge, 2025
[7] Li et al., From Generation to Judgment: Opportunities and Challenges of LLM-as-a-judge, arxiv:2411.16594 , 2025. Survey che documenta come le metriche tradizionali (matching-based) falliscano in scenari open-ended e dinamici, e come gli LLM offrano valutazioni multi-dimensionali.