ChatGPT è stato reso disponibile al pubblico il 30 novembre 2022, e a marzo del 2023, OpenAI ha annunciato l’accesso tramite API per i modelli ChatGPT. Ma cosa esattamente è ChatGPT e come funziona?
LSTM è morto. Lunga vita ai Transformer!
ChatGPT fa parte della famiglia di modelli linguistici noti come Generative Pre-trained Transformer (GPT). Questi modelli si basano su un’architettura di rete neurale chiamata Transformer, che rappresenta una tecnologia relativamente recente nell’ambito dell’elaborazione del linguaggio naturale (NLP).
I Transformers sono stati introdotti per la prima volta nel 2017 nel paper intitolato “Attention is all you need” di Vaswani et al. pubblicato da Google Research:
In this work we propose the Transformer, a model architecture eschewing recurrence and instead relying entirely on an attention mechanism to draw global dependencies between input and output. The Transformer allows for significantly more parallelization … the Transformer is the first transduction model relying entirely on self-attention to compute representations of its input and output without using sequence-aligned RNNs or convolution.
– Attention Is All You Need, 2017
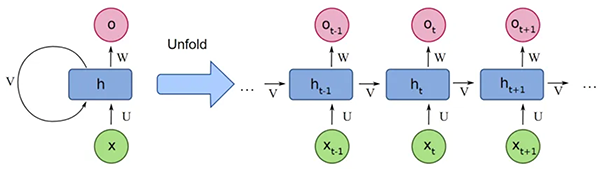
I Transformer sono una risposta ai limiti dei modelli Seq2seq allora dominanti, come le Reccurent Neural Network (RNN) e Long Short-Term Memory (LSTM).
Questi modelli sequenziali impiegavano molto tempo per il training perchè elaboravano i tokens in sequenza: ogni nodo riceve l’input corrente e uno stato nascosto (hidden state) dal passo precedente.
L’input corrente rappresenta il dato corrente nella sequenza, mentre lo stato nascosto contiene informazioni sull’elaborazione precedente. Ad ogni passaggio, l’input corrente e lo stato nascosto vengono combinati per produrre un nuovo stato nascosto. Ciò significava che più lunga era la sequenza, più lungo era il tempo di training.
Supponiamo di voler tradurre una frase dall’inglese al francese.
|
1 |
the european economic area |
Utilizzando le RNN la frase verrebbe tradotta un token alla volta e poi restituirrebbe sequenzialmente il loro equivalente in francese. Sappiamo però che nel linguaggio naturale, l’ordine delle parole è importante e non possono essere mescolate perché modificano la grammatica e quindi la semantica effettiva di una frase.
Non a caso la seguente traduzione in francese risulterebbe sbagliata:
|
1 |
la européenne economique zone |
Un altro limite delle architetture RNN è che, quando si elaborano grandi sequenze di testo, come lunghi paragrafi, tendono a dimenticare le informazioni dei primi token man mano che incorporano quelli nuovi.
Transformers
La rivoluzione dei Transformer risiede nell’abbandono del meccanismo di ricorrenza delle RNN, a favore di un approccio basato sulla self-attention. Questo ha portato a un notevole incremento nella velocità di addestramento e, teoricamente, alla capacità di catturare sequenze più lunghe e comprendere le dipendenze all’interno di una frase. Nonostante il diagramma del paper originale possa sembrare un po’ intimidatorio, la rivoluzione dei Transformer può essere riassunta in tre concetti principali:
|
1 2 3 |
1 – Positional encoding 2 – Attention 3 – Self attention |
![]()
Il positional encoding si occupa di fornire informazioni sulla posizione dei tokens all’interno di una sequenza. Dato che i Transformers non hanno un’architettura sequenziale come le RNN, l’encoding posizionale fornisce un modo per introdurre l’informazione sulla posizione dei tokens già in fase di pre-processing della frase, consentendo al modello di comprendere la struttura della frase. Questo significa che il compito di comprendere l’ordine dei token non è più affidato alla struttura della rete neurale, ma ai dati stessi. In questo modo, durante il training della rete neurale, essa impara a interpretare la codifica attribuendo importanza alle parole basandosi sui dati.
La self-attention permette invece ai Transformers di catturare le relazioni contestuali tra le parole di una frase, assegnando pesi differenti a ciascuna parola in base alla sua rilevanza nel contesto. Ciò permette di comprendere meglio il significato delle parole all’interno di una frase e di gestire la dipendenza a lungo termine tra le parole stesse.
La combinazione di self-attention e positional encoding nei Transformers consente di modellare in modo accurato le relazioni complesse tra le parole, catturando il contesto e la struttura delle frasi. Questa innovazione ha portato a notevoli miglioramenti nelle prestazioni dei modelli di elaborazione del linguaggio naturale (NLP), aprendo anche nuove possibilità nel campo della visione artificiale (Computer Vision, CV).
Sitografia
2014
[0] Christopher Olah, Deep Learning, NLP, and Representations, blog post, 7/07/2014
2015
[0] Christopher Olah, Understanding LSTM Networks, blog post, 27/07/2015
2018
[0] Jay Alammar, “The Ilustrated Transformer” blog post, 2018
[1] Lilian Weng, “Attention? Attention!!” blog post, 24/06/2018
[2] Akash Nair, Long Short Term Memory Networks, 13/12/2018
2019
[0] Peter Bloem, “Transformers from scratch” blog post, 18/08/2019
[1] Amirhossein Kazemnejad, Transformer Architecture: The Positional Encoding, , blog post, 10/09/2019
2020
[0] Eduardo Muñoz, Attention is all you need: Discovering the Transformer paper, Medium, 2/11/2020
2021
[0] Jonathan Kernes, Master Positional Encoding: Part I, 15/02/2021
[1] Jonathan Kernes, Master Positional Encoding: Part II, 25/02/2021
[2] Naoki Shibuya, Transformer’s Positional Encoding: How Does It Know Word Positions Without Recurrence?, 31/10/2021
2022
[0] Stefania Cristina, The Transformer Attention Mechanism, Machine Learning Mastery, 15/09/2022
[1] Stefania Cristina, The Transformer Model, Machine Learning Mastery, 18/09/2022
[2] About Mehreen Saeed, A Gentle Introduction to Positional Encoding in Transformer Models, Part 1, Machine Learning Mastery, 20/09/2022
2023
[0] Vincenzo Cosenza , L’intelligenza artificiale trasformerà i motori di ricerca?, 11/02/2023
[1] Dario D’Elia, Tutto su ChatGPT: che cos’è, come si usa e cosa permette di fare, Wired, 2023
Videografia
[0] Transformers, explained: Understand the model behind GPT, BERT, and T5
[1] What are Large Language Models (LLMs)?